

Capítulo 52 – Arquitetura de Redes Neurais Gated Recurrent Unit (GRU)
Neste capítulo estudaremos um tipo realmente fascinante de rede neural. Introduzido por Cho, et al. em 2014, a GRU (Gated Recurrent Unit) visa resolver o problema da dissipação do gradiente que é comum em uma rede neural recorrente padrão. A GRU também pode ser considerada uma variação da LSTM porque ambas são projetadas de maneira semelhante e, em alguns casos, produzem resultados igualmente excelentes. Para acompanhar este capítulo você precisa ter concluído os capítulos anteriores.
O Problema, Memória de Curto Prazo
Redes neurais recorrentes sofrem de memória de curto prazo. Se uma sequência for longa o suficiente, elas terão dificuldade em transportar informações das etapas anteriores para as posteriores. Portanto, se você estiver tentando processar um parágrafo de texto para fazer previsões, as RNNs poderão deixar de fora informações importantes desde o início.
Durante a etapa de backpropagation, as redes neurais recorrentes sofrem com o problema da dissipação do gradiente. Gradientes são valores usados para atualizar os pesos das redes neurais. O problema da dissipação do gradiente é quando o gradiente diminui à medida que se propaga novamente ao longo do tempo. Se um valor de gradiente se torna extremamente pequeno, não contribui muito com o aprendizado.
Assim, nas redes neurais recorrentes, as camadas que recebem uma pequena atualização gradiente param de aprender. Portanto, como essas camadas não aprendem, as RNNs podem esquecer o que foi visto em sequências mais longas, tendo assim uma memória de curto prazo.
LSTM e GRU Como Solução
LSTM e GRU foram criadas como a solução para a memória de curto prazo. Elas têm mecanismos internos chamados portões que podem regular o fluxo de informações.
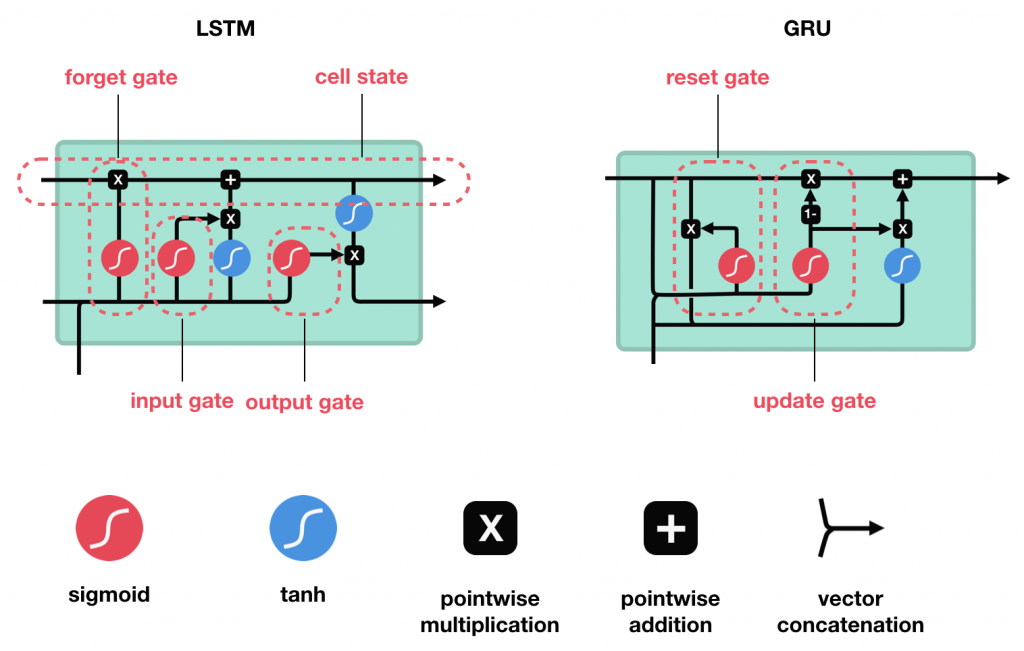
Esses portões podem aprender quais dados em uma sequência são importantes para manter ou jogar fora. Ao fazer isso, eles podem transmitir informações relevantes ao longo de uma longa cadeia de sequências para fazer previsões. Quase todos os resultados de última geração baseados em redes neurais recorrentes são alcançados com essas duas redes. LSTM e GRU podem ser usadas em reconhecimento de voz, síntese de fala e geração de texto. Você pode até usá-las para gerar legendas em vídeos.
Como as GRUs Funcionam?
A GRU é a nova geração de redes neurais recorrentes e é bastante semelhante a uma LSTM. As GRUs se livraram do estado da célula e usaram o estado oculto para transferir informações. Essa arquitetura possui apenas dois portões, um portão de redefinição (reset gate) e um portão de atualização (update date). As GRUs são uma versão melhorada da rede neural recorrente padrão. Mas o que as torna tão especiais e eficazes?
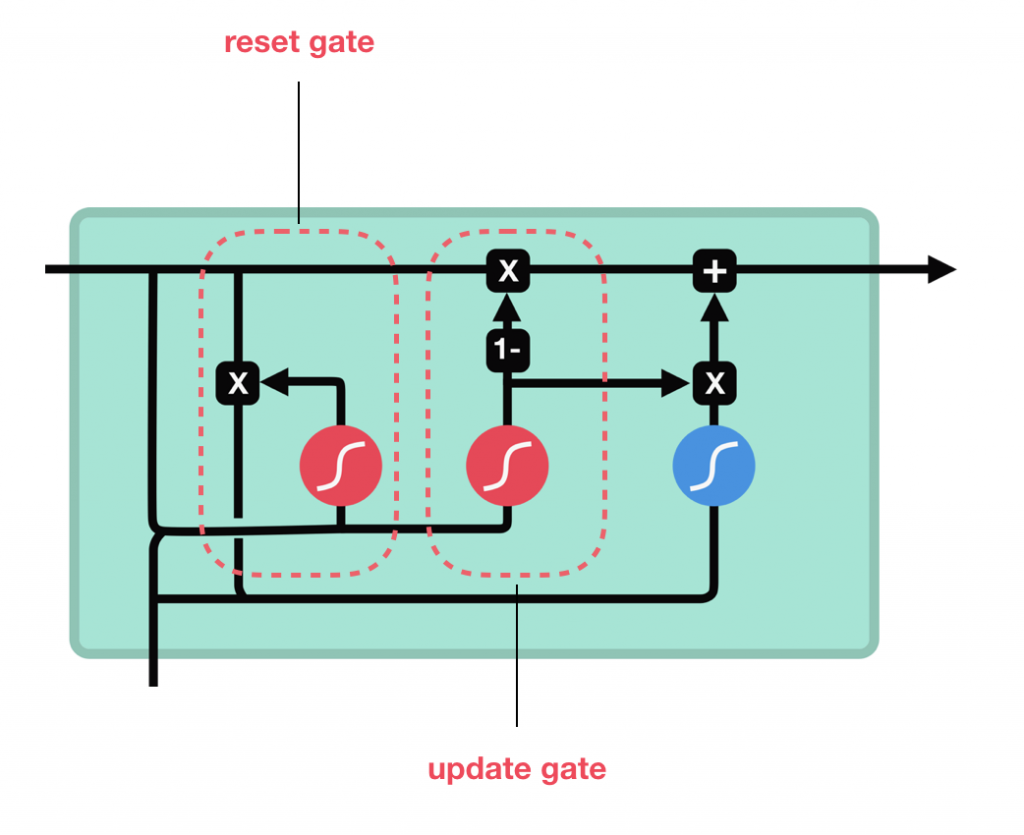
Para resolver o problema da dissipação do gradiente de uma RNN padrão, a GRU usa dois portões, reset e update gate. Basicamente, eles são dois vetores que decidem quais informações devem ser passadas para a saída. O que há de especial neles é que eles podem ser treinados para manter informações de muito tempo atrás, sem dissipá-las com o tempo ou remover informações irrelevantes para a previsão.
A estrutura da GRU permite capturar adaptativamente dependências de grandes sequências de dados sem descartar informações de partes anteriores da sequência. Isso é alcançado através de suas unidades de portões, semelhantes às das LSTMs. Esses portões são responsáveis por regular as informações a serem mantidas ou descartadas a cada etapa do tempo.
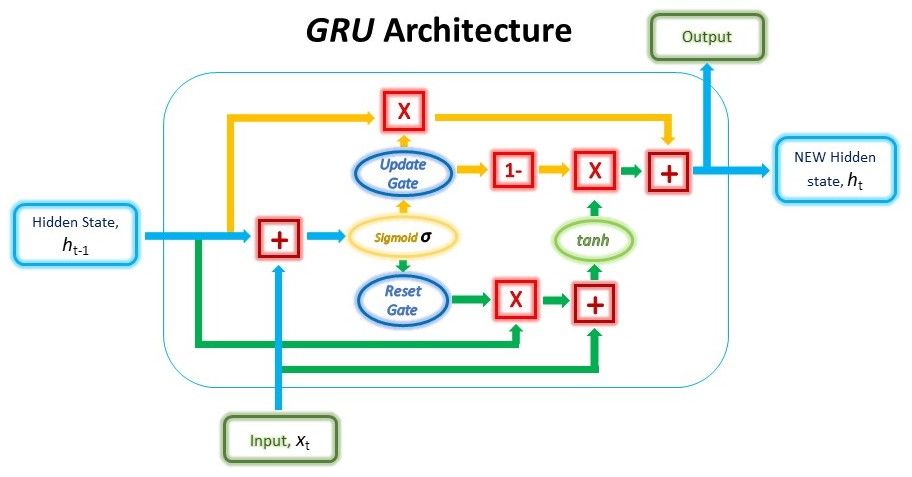
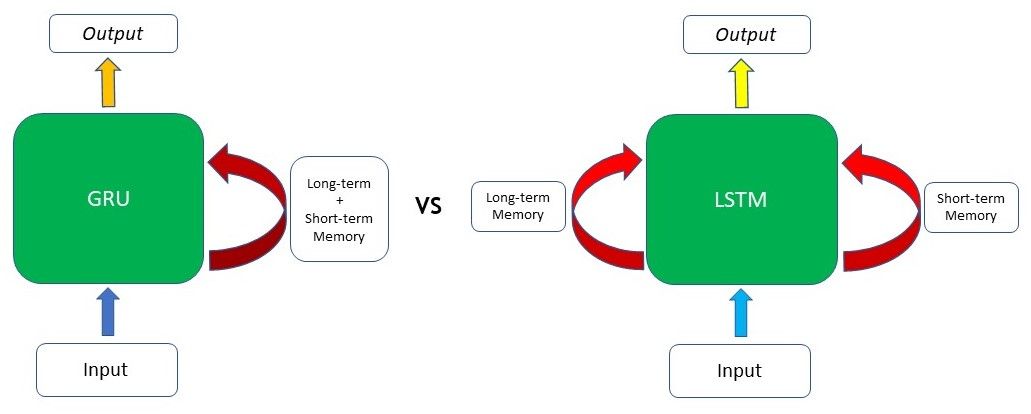
A capacidade da GRU de manter dependências ou memória de longo prazo decorre dos cálculos na célula da GRU para produzir o estado oculto. Enquanto as LSTMs têm dois estados diferentes passados entre as células – o estado da célula e o estado oculto, que carregam a memória de longo e curto prazo, respectivamente – as GRUs têm apenas um estado oculto transferido entre as etapas do tempo. Esse estado oculto é capaz de manter as dependências de longo e curto prazo ao mesmo tempo, devido aos mecanismos de restrição e cálculos pelos quais o estado oculto e os dados de entrada passam.
Assim como os portões das LSTMs, os portões na GRU são treinados para filtrar seletivamente qualquer informação irrelevante, mantendo o que é útil. Esses portões são essencialmente vetores contendo valores entre 0 e 1 que serão multiplicados com os dados de entrada e / ou estado oculto. Um valor 0 nos vetores indica que os dados correspondentes no estado de entrada ou oculto não são importantes e, portanto, retornarão como zero. Por outro lado, um valor 1 no vetor significa que os dados correspondentes são importantes e serão usados.
No próximo capítulo veremos os detalhes matemáticos por trás da GRU, uma das arquiteturas mais interessantes de Deep Learning e que tem obtido resultados formidáveis especialmente em Processamento de Linguagem Natural.
Até o próximo capítulo!
Referências:
Customizando Redes Neurais com Funções de Ativação Alternativas
Illustrated Guide to LSTM’s and GRU’s: A step by step explanation
A Recursive Recurrent Neural Network for Statistical Machine Translation
Sequence to Sequence Learning with Neural Networks
Recurrent Neural Networks Cheatsheet
On the difficulty of training recurrent neural networks
A Beginner’s Guide to LSTMs and Recurrent Neural Networks
Long Short-Term Memory (LSTM): Concept
Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs
Recurrent Neural Networks Tutorial, Part 3 – Backpropagation Through Time and Vanishing Gradients
Practical Recommendations for Gradient-Based Training of Deep Architectures
Gradient-Based Learning Applied to Document Recognition
Neural Networks & The Backpropagation Algorithm, Explained
Neural Networks and Deep Learning
Recurrent neural network based language model
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition