

Capítulo 58 – Introdução aos Autoencoders
Até aqui neste livro descrevemos arquiteturas de redes neurais profundas (Deep Learning) usadas em aprendizagem supervisionada, na qual rotulamos exemplos de treinamento, fornecendo ao algoritmo dados de entrada (X) e de saída (Y). Agora, suponha que tenhamos apenas um conjunto de exemplos de treinamento não rotulados {x1, x2, x3,…}, onde x (i) ∈ℜn. Uma rede neural Autoencoder é um algoritmo de aprendizado não supervisionado que aplica backpropagation, definindo os valores de destino como iguais às entradas. Ou seja, usa y (i) = x (i). Estudaremos essa arquitetura de Deep Learning a partir de agora.
O que são Autoencoders?
Os Autoencoders são uma técnica de aprendizado não supervisionado, na qual usamos as redes neurais para a tarefa de aprendizado de representação. Especificamente, projetaremos uma arquitetura de rede neural de modo a impor um gargalo na rede que força uma representação de conhecimento compactada da entrada original. Se os recursos de entrada fossem independentes um do outro, essa compressão e reconstrução subsequente seriam uma tarefa muito difícil. No entanto, se houver algum tipo de estrutura nos dados (ou seja, correlações entre os recursos de entrada), essa estrutura poderá ser aprendida e consequentemente aproveitada ao forçar a entrada através do gargalo da rede.
Autoencoders (AE) são redes neurais que visam copiar suas entradas para suas saídas. Eles trabalham compactando a entrada em uma representação de espaço latente e, em seguida, reconstruindo a saída dessa representação. Esse tipo de rede é composto de duas partes:
Codificador (Encoder): é a parte da rede que compacta a entrada em uma representação de espaço latente (codificando a entrada). Pode ser representado por uma função de codificação h = f (x).
Decodificador (Decoder): Esta parte tem como objetivo reconstruir a entrada da representação do espaço latente. Pode ser representado por uma função de decodificação r = g (h).
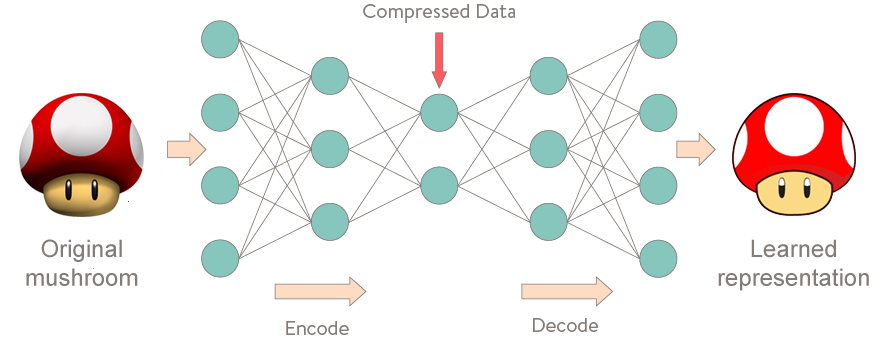
O Autoencoder tenta aprender uma função h W, b (x) ≈ x. Em outras palavras, ele está tentando aprender uma aproximação com a função de identidade, de modo a gerar x’ semelhante a x. A função de identidade parece uma função particularmente trivial para tentar aprender; mas colocando restrições na rede, como limitando o número de unidades ocultas, podemos descobrir uma estrutura interessante sobre os dados. Como um exemplo concreto, suponha que as entradas x sejam os valores de intensidade de pixel de uma imagem 10 × 10 (100 pixels), portanto n = 100 e haja s = 50 unidades ocultas na camada L2. Observe que também temos y∈ℜ100. Como existem apenas 50 unidades ocultas, a rede é forçada a aprender uma representação “compactada” da entrada. Ou seja, dado apenas o vetor de ativações de unidades ocultas, ele deve tentar ”reconstruir” a entrada de 100 pixels x. Se a entrada fosse completamente aleatória – digamos, cada xi provém de um ID Gaussiano independente dos outros recursos, essa tarefa de compactação seria muito difícil. Mas se houver estrutura nos dados, por exemplo, se alguns dos recursos de entrada estiverem correlacionados, esse algoritmo poderá descobrir algumas dessas correlações. De fato, esse Autoencoder simples geralmente acaba aprendendo uma representação de baixa dimensão muito semelhante aos PCAs (Principal Component Analysis).
Nosso argumento acima se baseava no número de unidades ocultas s sendo pequenas. Mas mesmo quando o número de unidades ocultas é grande (talvez até maior que o número de pixels de entrada), ainda podemos descobrir uma estrutura interessante, impondo outras restrições à rede. Em particular, se impusermos uma restrição de “esparsidade” nas unidades ocultas, o Autoencoder ainda descobrirá uma estrutura interessante nos dados, mesmo que o número de unidades ocultas seja grande.
Por que copiar a entrada para a saída?
Se o único objetivo dos Autoencoders fosse copiar a entrada para a saída, eles seriam inúteis. De fato, esperamos que, treinando o Autoencoder para copiar a entrada para a saída, a representação latente h tenha propriedades úteis.
Isso pode ser conseguido criando restrições na tarefa de cópia. Uma maneira de obter recursos úteis do Autoencoder é restringir h a ter dimensões menores que x; nesse caso, o Autoencoder é chamado de incompleto. Ao treinar uma representação incompleta, forçamos o Autoencoder a aprender os recursos mais importantes dos dados de treinamento. Se for dada muita capacidade ao Autoencoder, ele poderá aprender a executar a tarefa de cópia sem extrair nenhuma informação útil sobre a distribuição dos dados. Isso também pode ocorrer se a dimensão da representação latente for a mesma que a entrada e, no caso de excesso de conclusão, em que a dimensão da representação latente for maior que a entrada.
Nesses casos, mesmo um codificador linear e um decodificador linear podem aprender a copiar a entrada na saída sem aprender nada útil sobre a distribuição de dados. Idealmente, alguém poderia treinar qualquer arquitetura de Autoencoder com sucesso, escolhendo a dimensão do código e a capacidade do codificador e decodificador com base na complexidade da distribuição a ser modelada.
Para que são usados os Autoencoders?
Atualmente, o denoising de dados (remoção de ruídos) e a redução de dimensionalidade para visualização de dados são considerados duas principais aplicações práticas interessantes de Autoencoders. Com restrições de dimensionalidade e esparsidade apropriadas, os Autoencoders podem aprender projeções de dados mais interessantes que o PCA ou outras técnicas básicas.
Os Autoencoders aprendem automaticamente a partir de exemplos de dados. Isso significa que é fácil treinar instâncias especializadas do algoritmo que terão bom desempenho em um tipo específico de entrada e que não requer nenhuma nova engenharia de recursos, apenas os dados de treinamento apropriados.
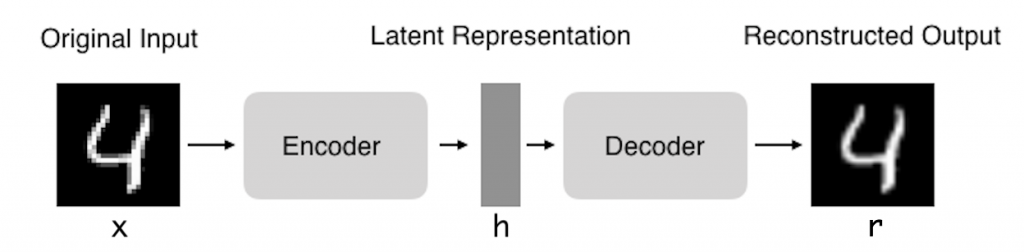
Outra aplicação dos Autoencoders é como tarefa preliminar ao reconhecimento de imagens com CNNs (Redes Neurais Convolucionais). Observando a imagem acima você percebe que a saída do Autoencoder é a imagem do número 4 muito mais suave. Ou seja, aplicamos os Autoencoders para remover ruído dos dados (denoising) e depois usamos a saída dos Autoencoders para treinar um modelo CNN.
Os Autoencoders são treinados para preservar o máximo de informações possível quando uma entrada é passada pelo codificador e depois pelo decodificador, mas também são treinados para fazer com que a nova representação tenha várias propriedades agradáveis. Diferentes tipos de Autoencoders visam atingir diferentes tipos de propriedades.
Referências:
Deep Learning Para Aplicações de IA com PyTorch e Lightning
Customizando Redes Neurais com Funções de Ativação Alternativas
Autoencoders – Unsupervised Learning
Practical Recommendations for Gradient-Based Training of Deep Architectures
Gradient-Based Learning Applied to Document Recognition
Neural Networks & The Backpropagation Algorithm, Explained
Recurrent neural network based language model
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition