

Capítulo 62 – O Que é Aprendizagem Por Reforço?
Todas as arquiteturas de Deep Learning que estudamos até aqui neste livro podem ser classificadas em duas categorias de aprendizagem de máquina (você já sabe que Deep Learning é sub-categoria de Machine Learning, que por sua vez é uma sub-categoria de Inteligência Artificial):
- Aprendizagem Supervisionada – quando apresentamos ao algoritmo dados de entrada e as respectivas saídas.
- Aprendizagem Não Supervisionada – quando apresentamos somente os dados de entrada e o algoritmo descobre as saídas.
Mas existe uma terceira categoria de aprendizagem, chamada de Aprendizagem Por Reforço (ou Reinforcement Learning), muito usada em Games e Robótica e que vem obtendo resultados cada vez melhores. A Aprendizagem Por Reforço é a principal técnica por trás do AlphaGo e está muito bem retratada no documentário do mesmo nome: AlphaGo.
Serão diversos capítulos dedicados a esta técnica e à sua extensão, o Deep Reinforcement Learning. Vamos começar definindo o que é Aprendizagem Por Reforço.
O Que é Aprendizagem Por Reforço?
A Aprendizagem Por Reforço é o treinamento de modelos de aprendizado de máquina para tomar uma sequência de decisões. O agente aprende a atingir uma meta em um ambiente incerto e potencialmente complexo. No aprendizado por reforço, o sistema de inteligência artificial enfrenta uma situação. O computador utiliza tentativa e erro para encontrar uma solução para o problema. Para que a máquina faça o que o programador deseja, a inteligência artificial recebe recompensas ou penalidades pelas ações que executa. Seu objetivo é maximizar a recompensa total.
Embora o Cientista de Dados ou o Engenheiro de IA defina a política de recompensa – isto é, as regras do jogo – ele não dá ao modelo nenhuma dica ou sugestão de como resolver o jogo. Cabe ao modelo descobrir como executar a tarefa para maximizar a recompensa, começando com testes totalmente aleatórios e terminando com táticas sofisticadas. Ao alavancar o poder da pesquisa e de muitas tentativas, o aprendizado por reforço é atualmente a maneira mais eficaz de sugerir a criatividade da máquina. Ao contrário dos seres humanos, a inteligência artificial pode reunir experiência de milhares de jogos paralelos se um algoritmo de aprendizado por reforço for executado em uma infraestrutura de computador suficientemente poderosa.
Exemplo:
O problema é o seguinte: Temos um agente e uma recompensa, com muitos obstáculos no meio, como nesta imagem abaixo. O agente deve encontrar o melhor caminho possível para alcançar a recompensa e quando encontrar um obstáculo, deve ser penalizado (pois ele deve escolher o caminho sem obstáculos). Com a Aprendizagem Por Reforço, podemos treinar o agente para encontrar o melhor caminho.

Desafios do Aprendizado Por Reforço
O principal desafio do aprendizado por reforço está na preparação do ambiente de simulação, que depende muito da tarefa a ser executada. Quando o modelo é treinado em jogos de Xadrez, Go ou Atari, a preparação do ambiente de simulação é relativamente simples. Quando se trata de construir um modelo capaz de dirigir um carro autônomo, a construção de um simulador realista é crucial antes de deixar o carro andar na rua. O modelo precisa descobrir como frear ou evitar uma colisão em um ambiente seguro. Transferir o modelo do ambiente de treinamento para o mundo real é onde as coisas ficam complicadas.
Escalar e ajustar a rede neural que controla o agente é outro desafio. Não há como se comunicar com a rede a não ser através do sistema de recompensas e penalidades. Isso pode levar a um esquecimento catastrófico, em que a aquisição de novos conhecimentos faz com que alguns dos antigos sejam apagados da rede. Ou seja, precisamos guardar o aprendizado na “memória” do agente.
Outro desafio é alcançar um ótimo local – ou seja, o agente executa a tarefa como está, mas não da maneira ideal ou necessária. Um “saltador” pulando como um canguru em vez de fazer o que se esperava dele com pequenos saltos é um ótimo exemplo. Por fim, existem agentes que otimizarão o prêmio sem executar a tarefa para a qual foram projetados.
O Que Distingue o Aprendizado Por Reforço do Aprendizado Profundo e do Aprendizado de Máquina?
De fato, não há uma divisão clara entre aprendizado de máquina, aprendizado profundo e aprendizado por reforço. É como uma relação paralelogramo – retângulo – quadrado, em que o aprendizado de máquina é a categoria mais ampla e o aprendizado por reforço é o mais estreito.
Da mesma forma, o aprendizado por reforço é uma aplicação especializada de técnicas de Deep Learning e Machine Learning, projetada para resolver problemas de uma maneira específica.
Embora as ideias pareçam divergir, não há uma divisão acentuada entre esses subtipos. Além disso, eles se mesclam nos projetos, pois os modelos são projetados para não se ater ao “tipo puro”, mas para executar a tarefa da maneira mais eficaz possível. Portanto, “o que distingue precisamente o aprendizado de máquina, o aprendizado profundo e o aprendizado por reforço” é, na verdade, uma pergunta difícil de responder. Mas vamos definir cada um deles!
Aprendizado de Máquina é uma forma de IA na qual os computadores têm a capacidade de melhorar progressivamente o desempenho de uma tarefa específica com dados, sem serem diretamente programados. Essa é a definição de Arthur Lee Samuel. Ele cunhou o termo “aprendizado de máquina”, do qual existem dois tipos, aprendizado de máquina supervisionado e não supervisionado.
O aprendizado de máquina supervisionado acontece quando um programador pode fornecer um rótulo para cada entrada de treinamento no sistema de aprendizado de máquina.
O aprendizado não supervisionado ocorre quando o modelo é fornecido apenas com os dados de entrada, mas sem rótulos explícitos. Ele precisa pesquisar os dados e encontrar a estrutura ou os relacionamentos ocultos. O Cientista de Dados pode não saber qual é a estrutura ou o que o modelo de aprendizado de máquina irá encontrar.
O Aprendizado Profundo consiste em várias camadas de redes neurais, projetadas para executar tarefas mais sofisticadas. A construção de modelos de aprendizado profundo foi inspirada no design do cérebro humano, mas simplificada. Os modelos de aprendizado profundo consistem em algumas camadas de rede neural que são, em princípio, responsáveis por aprender gradualmente recursos mais abstratos sobre dados específicos.
Embora as soluções de aprendizado profundo sejam capazes de fornecer resultados maravilhosos, em termos de escala, elas não são páreo para o cérebro humano. Cada camada usa o resultado de uma anterior como entrada e toda a rede é treinada como um todo. O conceito central de criar uma rede neural artificial não é novo, mas apenas recentemente o hardware moderno forneceu energia computacional suficiente para treinar efetivamente essas redes, expondo um número suficiente de exemplos. A adoção estendida trouxe estruturas como TensorFlow, Keras e PyTorch, as quais tornaram a construção de modelos de aprendizado de máquina muito mais conveniente.
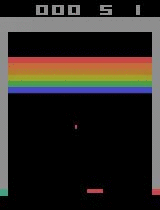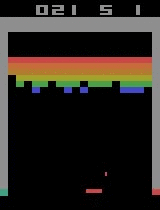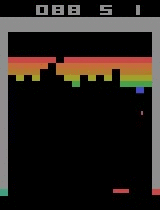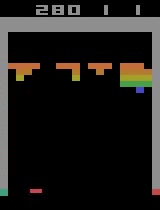
O Aprendizado Por Reforço, como declarado acima, emprega um sistema de recompensas e penalidades para obrigar o computador a resolver um problema sozinho. O envolvimento humano é limitado à mudança do ambiente e ao ajuste do sistema de recompensas e penalidades. Como o computador maximiza a recompensa, ele está propenso a procurar maneiras inesperadas de fazê-lo. O envolvimento humano é focado em impedir que ele explore o sistema e motive a máquina a executar a tarefa da maneira esperada. O aprendizado por reforço é útil quando não existe uma “maneira adequada” de executar uma tarefa, mas existem regras que o modelo deve seguir para desempenhar corretamente suas tarefas. Abaixo a performance de um agente sendo treinado em um jogo clássico do Atari.
Performance inicial do agente:

Após 15 minutos de treinamento:
Após 30 minutos de treinamento:

Em particular, se a inteligência artificial vai dirigir um carro ou aprender a jogar alguns clássicos do Atari, pode ser considerado um marco intermediário significativo. Uma aplicação potencial do aprendizado por reforço em veículos autônomos é uma das aplicações mais trabalhadas nos dias de hoje em todo mundo. Um desenvolvedor é incapaz de prever todas as situações futuras da estrada, portanto, deixar o modelo treinar-se com um sistema de penalidades e recompensas em um ambiente variado é possivelmente a maneira mais eficaz da IA ampliar a experiência que possui e coleta e assim aprender a conduzir um veículo autônomo sem que seja explicitamente programada para isso.
Continuaremos no próximo capítulo!
Referências:
Inteligência Artificial Aplicada a Finanças
Customizando Redes Neurais com Funções de Ativação Alternativas
What is reinforcement learning? The complete guide
Practical Recommendations for Gradient-Based Training of Deep Architectures
Gradient-Based Learning Applied to Document Recognition
Neural Networks & The Backpropagation Algorithm, Explained
Recurrent neural network based language model
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition