

Capítulo 86 – Como Funcionam os Transformadores em Processamento de Linguagem Natural – Parte 1
A partir de agora e nos próximos capítulos vamos compreender o funcionamento dos Transformadores, uma das técnicas mais avançadas da atualidade em Inteligência Artificial, especialmente no Processamento de Linguagem Natural.
Os Transformadores não são tão difíceis de entender. É a combinação de todos os conceitos que pode tornar a compreensão complexa, incluindo a atenção. É por isso que vamos construir lentamente todos os conceitos fundamentais. Não tenha pressa. Não existe atalho para o aprendizado.
Com Redes Neurais Recorrentes (RNNs), costumamos tratar frases sequencialmente para manter a ordem da frase no lugar (já vimos isso em capítulos anteriores deste livro). Para satisfazer esse design, cada componente RNN (camada) precisa da saída anterior (oculta). Como tal, os cálculos LSTM empilhados são executados sequencialmente.
Até que os Transformadores aparecessem! O bloco de construção fundamental de um Transformador é a auto-atenção. Para começar, precisamos superar o processamento sequencial, recorrência e LSTMs!
Como?
Simplesmente alterando a representação de entrada!
Representando a Frase de Entrada
A revolução do Transformador começou com uma pergunta simples: por que não alimentamos toda a sequência de entrada? Sem dependências entre estados ocultos! Isso pode ser legal!
Como exemplo, a frase “Hello, I love you” (“olá, eu te amo”):
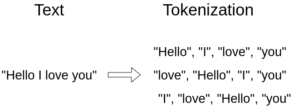
Essa etapa de processamento geralmente é chamada de tokenização e é a primeira das três etapas antes de alimentarmos a entrada no modelo. Isso vale para qualquer técnica em PLN, conforme mostramos no curso de Processamento de Linguagem Natural na DSA.
Portanto, em vez de uma sequência de elementos, agora temos um conjunto. Conjuntos são uma coleção de elementos distintos, onde a disposição dos elementos no conjunto não importa.
Em outras palavras, a ordem é irrelevante. Indicamos a entrada definida como:
![]()
Os elementos da sequência xi são chamados de tokens.
Após a tokenização, projetamos palavras em um espaço geométrico distribuído ou simplesmente construímos embeddings de palavras.
Word Embeddings
Em geral, um embedding é uma representação de um símbolo (palavra, caractere, frase) em um espaço distribuído de baixa dimensão de vetores de valor contínuo.
Palavras não são símbolos discretos. Elas estão fortemente correlacionadas uma com a outra. É por isso que quando as projetamos em um espaço euclidiano contínuo, podemos encontrar associações entre elas. Para compreender o que é espaço euclidiano recomendamos nosso curso de Matemática Para Data Science.
Então, dependendo da tarefa, podemos empurrar os embedding de palavras para mais longe ou mantê-los juntos.
Idealmente, um embedding captura a semântica da entrada, colocando entradas semanticamente semelhantes próximas no espaço de embedding.
Na linguagem natural, podemos encontrar significados de palavras semelhantes ou até mesmo estruturas sintáticas semelhantes (ou seja, os objetos são agrupados). Em qualquer caso, quando você os projeta no espaço 2D ou 3D, você pode identificar visualmente alguns clusters.
Para obter um exemplo prático das word embeddings, experimente brincar com este notebook fornecido pela equipe do TensorFlow.
Seguindo em frente, criaremos um truque para fornecer alguma noção de ordem no conjunto.
Codificações Posicionais
Ao converter uma sequência em um conjunto (tokenização), você perde a noção de ordem.
Você consegue encontrar a ordem das palavras (tokens) na sequência: “Hello, I love you”? Provavelmente sim! Mas e quanto a 30 palavras não ordenadas?
Lembre-se de que o aprendizado de máquina envolve escala. A rede neural certamente não consegue entender nenhuma ordem em um conjunto.
Uma vez que os Transformadores processam sequências como conjuntos, eles são, em teoria, invariantes de permutação.
Vamos ajudá-los a ter um senso de ordem alterando ligeiramente os embeddings com base na posição. Oficialmente, a codificação posicional é um conjunto de pequenas constantes, que são adicionadas ao vetor de embeddings de palavras antes da primeira camada de auto-atenção.
Portanto, se a mesma palavra aparecer em uma posição diferente, a representação real será um pouco diferente, dependendo de onde ela aparece na frase de entrada.
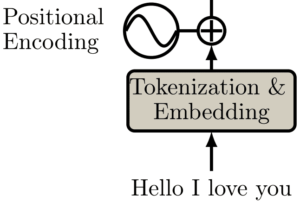
No artigo original do Transformador, os autores criaram a função senoidal para a codificação posicional. A função seno diz ao modelo para prestar atenção a um determinado comprimento de onda lambda λ.
Em nosso caso, o lambda λ será dependente da posição na frase e i é usado para distinguir entre posições ímpares e pares. Matematicamente:
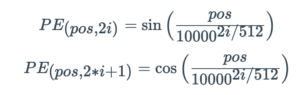
Isso contrasta com os modelos recorrentes, em que temos uma ordem, mas estamos lutando para prestar atenção aos tokens que não estão próximos o suficiente.
Agora podemos passar para a Parte 2. Até o próximo capítulo.
Os Transformadores estarão presentes na Formação IA Aplicada ao Direito, que será lançada em breve na DSA.
Referências:
Deep Learning Para Aplicações de IA com PyTorch e Lightning
Processamento de Linguagem Natural
Understanding Attention In Deep Learning
How Transformers work in deep learning and NLP: an intuitive introduction