

Capítulo 24 – Expandir Artificialmente os Dados de Treinamento
Vimos anteriormente que a precisão da classificação com o dataset MNIST caiu para porcentagens em torno de 80%, quando usamos apenas 1.000 imagens de treinamento. Não é de surpreender que isso aconteça, uma vez que menos dados de treinamento significam que nossa rede será exposta a menos variações na forma como os seres humanos escrevem dígitos. Vamos tentar treinar nossa rede de 30 neurônios ocultos com uma variedade de diferentes tamanhos de conjuntos de dados de treinamento, para ver como o desempenho varia.
Nós treinaremos usando um tamanho de mini-lote de 10, uma taxa de aprendizado η = 0,5, um parâmetro de regularização λ = 5.0 e a função de custo de entropia cruzada. Treinaremos por 30 épocas quando o conjunto completo de dados de treinamento for usado e aumentaremos o número de épocas proporcionalmente quando conjuntos de treinamento menores forem usados. Para garantir que o fator de decaimento do peso (weight decay factor) permaneça o mesmo nos conjuntos de treinamento, usaremos um parâmetro de regularização de λ = 5.0 quando o conjunto de dados de treinamento completo for usado, e reduziremos proporcionalmente quando conjuntos de treinamento menores forem usados. Observe esse gráfico:
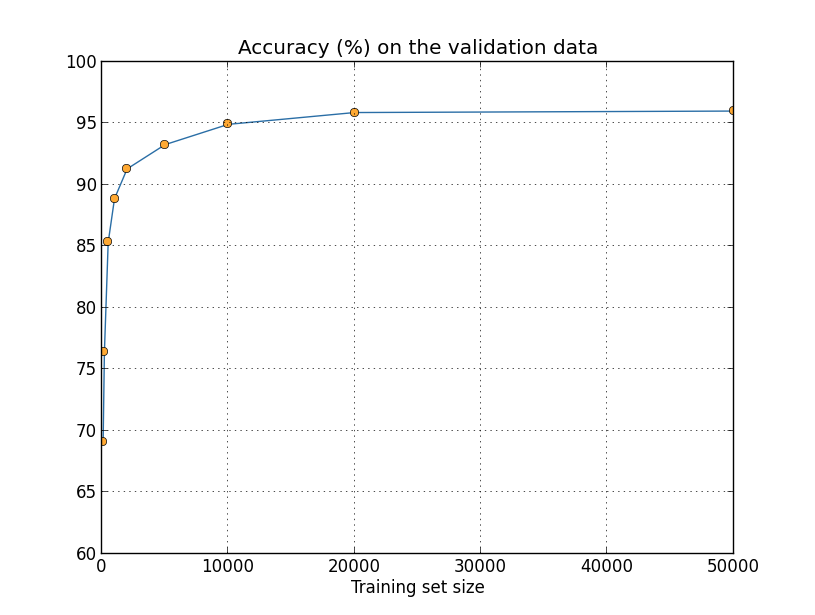
Como você pode ver analisando o gráfico acima, as precisões de classificação melhoram consideravelmente à medida que usamos mais dados de treinamento. Presumivelmente, essa melhoria continuaria se houvesse mais dados disponíveis. É claro que, olhando para o gráfico acima, parece que estamos chegando perto da saturação. Suponha, no entanto, que refizemos o gráfico com o tamanho do conjunto de treinamento plotado logaritmicamente:
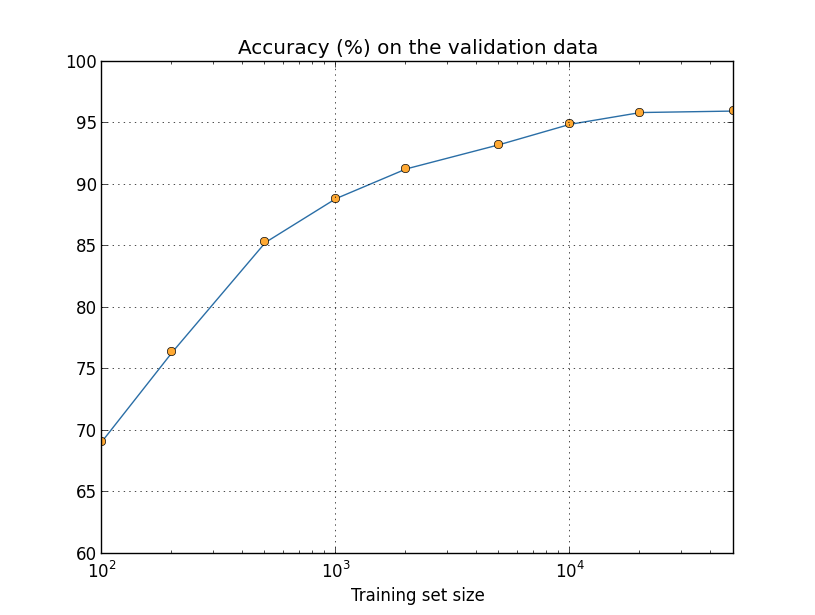
Parece claro que o gráfico ainda está subindo em direção aos 100% de precisão. Isso sugere que, se usássemos muito mais dados de treinamento – digamos, milhões ou até bilhões de amostras de dígitos manuscritos, em vez de apenas 50.000, provavelmente teríamos um desempenho consideravelmente melhor, mesmo nessa rede muito pequena.
Obter mais dados de treinamento é uma ótima ideia. Infelizmente, pode ser caro e nem sempre é possível na prática. No entanto, há outra técnica que pode funcionar quase tão bem, que é expandir artificialmente os dados de treinamento. Suponha, por exemplo, que tomemos uma imagem de treinamento MNIST, o dígito 5:

e rotacionamos por um pequeno ângulo, digamos 15 graus:

Ainda é reconhecivelmente o mesmo dígito. E ainda no nível do pixel é bem diferente de qualquer imagem atualmente nos dados de treinamento MNIST. É possível que adicionar essa imagem aos dados de treinamento possa ajudar nossa rede a aprender mais sobre como classificar os dígitos. Além do mais, obviamente, não estamos limitados a adicionar apenas uma imagem. Podemos expandir nossos dados de treinamento fazendo muitas rotações pequenas de todas as imagens de treinamento MNIST e, em seguida, usando os dados de treinamento expandidos para melhorar o desempenho de nossa rede.
Essa técnica é muito poderosa e tem sido amplamente usada. Vejamos alguns dos resultados de um artigo que aplicou diversas variações da técnica ao MNIST. Uma das arquiteturas de redes neurais que eles consideraram foi similar às que estamos usando, uma rede feedforward com 800 neurônios ocultos e usando a função de custo de entropia cruzada. Executando a rede com os dados de treinamento MNIST padrão, eles obtiveram uma precisão de classificação de 98,4% em seu conjunto de testes. Eles então expandiram os dados de treinamento, usando não apenas rotações, como descrevi acima, mas também traduzindo e distorcendo as imagens. Ao treinar no conjunto de dados expandido, aumentaram a precisão de sua rede para 98,9%.
Eles também experimentaram o que chamaram de “distorções elásticas”, um tipo especial de distorção de imagem destinada a emular as oscilações aleatórias encontradas nos músculos da mão. Usando as distorções elásticas para expandir os dados, eles alcançaram uma precisão ainda maior, 99,3%. Efetivamente, eles estavam ampliando a experiência de sua rede, expondo-a ao tipo de variações encontradas na caligrafia real. Caso queira aprender sobre estas técnicas, elas são estudadas em detalhes em Análise de Imagens com Inteligência Artificial.
Variações sobre essa técnica podem ser usadas para melhorar o desempenho em muitas tarefas de aprendizado, não apenas no reconhecimento de manuscrito. O princípio geral é expandir os dados de treinamento aplicando operações que reflitam a variação do mundo real. Não é difícil pensar em maneiras de fazer isso. Suponha, por exemplo, que você esteja construindo uma rede neural para fazer o reconhecimento de fala. Nós humanos podemos reconhecer a fala mesmo na presença de distorções como ruído de fundo e assim você pode expandir seus dados adicionando ruído de fundo. Também podemos reconhecer a fala se ela estiver acelerada ou desacelerada. Então, essa é outra maneira de expandir os dados de treinamento. Essas técnicas nem sempre são usadas – por exemplo, em vez de expandir os dados de treinamento adicionando ruído, pode ser mais eficiente limpar a entrada para a rede aplicando primeiro um filtro de redução de ruído. Ainda assim, vale a pena manter a ideia de expandir os dados de treinamento e buscar oportunidades para aplicar a técnica.
Agora você compreende melhor o poder do Big Data, pois com mais dados, em maior variedade e gerados em alta velocidade, conseguimos chegar a resultados nunca antes vistos em Inteligência Artificial. Vamos ver novamente como a precisão da nossa rede neural varia com o tamanho do conjunto de treinamento:
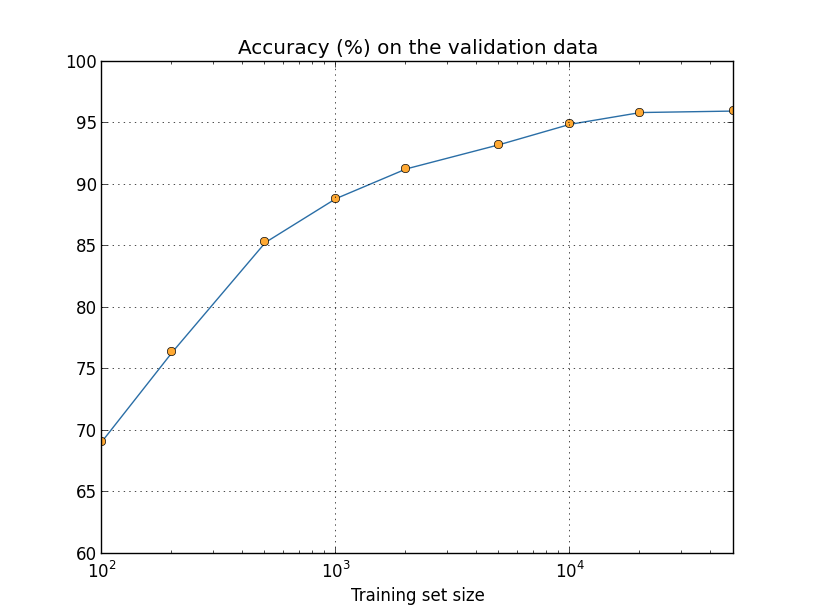
Suponha que, em vez de usar uma rede neural, usemos alguma outra técnica de aprendizado de máquina para classificar os dígitos. Por exemplo, vamos tentar usar as máquinas de vetores de suporte (SVMs). Não se preocupe se você não estiver familiarizado com SVMs, não precisamos entender seus detalhes (caso queira aprender sobre SVMs, elas são estudadas em detalhes em Machine Learning). Vamos usar o SVM fornecido pela biblioteca scikit-learn. Veja como o desempenho do SVM varia em função do tamanho do conjunto de treinamento. Eu tracei os resultados da rede neural também, para facilitar a comparação:
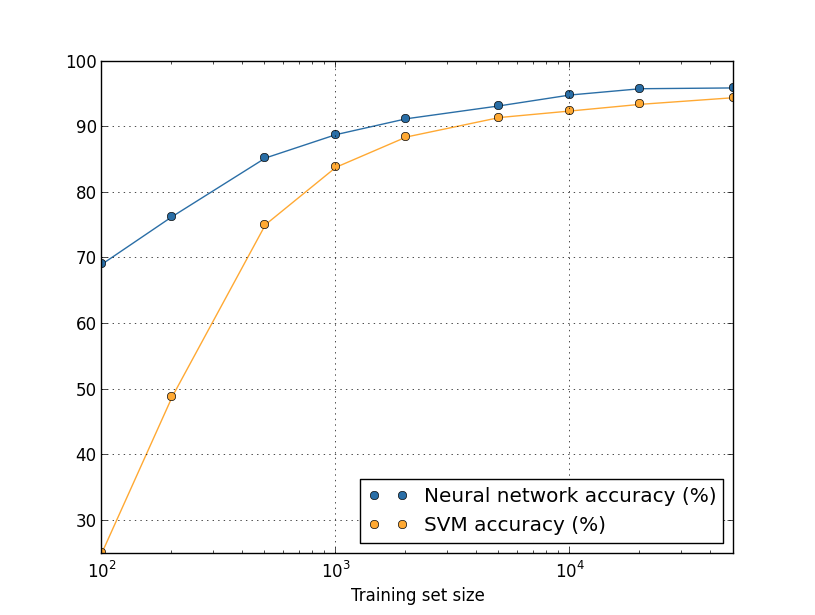
Provavelmente, a primeira coisa que chama a atenção sobre esse gráfico é que nossa rede neural supera o SVM para cada tamanho de conjunto de treinamento. Isso é bom, embora tenhamos usado as configurações prontas do SVM do scikit-learn, enquanto fizemos um bom trabalho customizando nossa rede neural. Um fato sutil, porém interessante, sobre o gráfico é que, se treinarmos o SVM usando 50.000 imagens, ele terá melhor desempenho (94,48% de precisão) do que a nossa rede neural quando treinado usando 5.000 imagens (precisão de 93,24%). Em outras palavras, mais dados de treinamento podem, às vezes, compensar diferenças no algoritmo de aprendizado de máquina usado.
Algo ainda mais interessante pode ocorrer. Suponha que estamos tentando resolver um problema usando dois algoritmos de aprendizado de máquina, algoritmo A e algoritmo B. Às vezes acontece que o algoritmo A superará o algoritmo B com um conjunto de dados de treinamento, enquanto o algoritmo B superará o algoritmo A com um conjunto diferente de dados de treinamento. Não vemos isso acima – seria necessário que os dois gráficos se cruzassem – mas a resposta correta à pergunta “O algoritmo A é melhor que o algoritmo B?” seria: “Qual o tamanho do conjunto de dados de treinamento que você está usando?”
Tudo isso é uma precaução a ter em mente, tanto ao fazer o desenvolvimento quanto ao ler artigos de pesquisa. Muitos artigos concentram-se em encontrar novos truques para obter melhor desempenho em conjuntos de dados de referência padrão. “Nossa técnica XPTO nos deu uma melhoria de X por cento no benchmark padrão Y” é uma forma canônica de alegação de pesquisa. Tais alegações são, com frequência, genuinamente interessantes, mas devem ser entendidas como aplicáveis apenas no contexto do conjunto de dados de treinamento específico usado. Imagine uma história alternativa na qual as pessoas que originalmente criaram o conjunto de dados de referência tinham uma concessão de pesquisa maior. Eles podem ter usado o dinheiro extra para coletar mais dados de treinamento. É perfeitamente possível que o “aprimoramento” devido à técnica de “XPTO” desapareça em um conjunto maior de dados. Em outras palavras, a suposta melhoria pode ser apenas um acidente da história.
A mensagem a ser retirada, especialmente em aplicações práticas, é que o que queremos é melhores algoritmos e melhores dados de treinamento. Não há problema em procurar algoritmos melhores, mas certifique-se de não estar se concentrando apenas em melhores algoritmos, excluindo a busca por mais ou melhores dados de treinamento.
Com isso concluímos nosso mergulho no overfitting e na regularização. Claro, voltaremos novamente ao assunto. Como já mencionamos várias vezes, o overfitting é um grande problema nas redes neurais, especialmente à medida que os computadores se tornam mais poderosos e temos a capacidade de treinar redes maiores. Como resultado, há uma necessidade premente de desenvolver técnicas poderosas de regularização para reduzir o overfitting, e esta é uma área extremamente ativa de pesquisa.
No próximo capítulo vamos tratar de um outro importante assunto: a inicialização de pesos. Até lá.
Referências:
Formação Engenheiro de Inteligência Artificial
Best practices for convolutional neural networks applied to visual document analysis
Neural Networks & The Backpropagation Algorithm, Explained
Scaling to very very large corpora for natural language disambiguation
Gradient-Based Learning Applied to Document Recognition
Neural Networks and Deep Learning
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition
Gradient Descent For Machine Learning
Pattern Recognition and Machine Learning
Understanding Activation Functions in Neural Networks
Redes Neurais, princípios e práticas
ImageNet Classification with Deep Convolutional Neural Networks
Improving neural networks by preventing co-adaptation of feature detectors