

Capítulo 9 – A Arquitetura das Redes Neurais
No capítulo 11 vamos desenvolver uma rede neural para classificação de dígitos manuscritos, usando linguagem Python (caso ainda não saiba trabalhar com a linguagem, comece agora mesmo com nosso curso online totalmente gratuito Fundamentos de Linguagem Python Para Análise de Dados e Data Science). Mas antes, vamos compreender a terminologia que será muito útil quando estivermos desenvolvendo nosso modelo, estudando a Arquitetura das Redes Neurais. Suponha que tenhamos a rede abaixo:
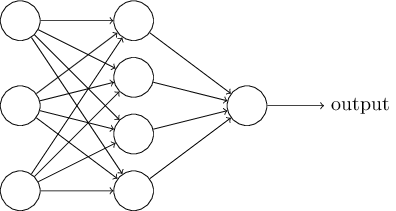
A camada mais à esquerda nesta rede é chamada de camada de entrada e os neurônios dentro da camada são chamados de neurônios de entrada. A camada mais à direita ou a saída contém os neurônios de saída ou, como neste caso, um único neurônio de saída. A camada do meio é chamada de camada oculta, já que os neurônios nessa camada não são entradas ou saídas. O termo “oculto” talvez soe um pouco misterioso – a primeira vez que ouvi o termo, pensei que devesse ter algum significado filosófico ou matemático profundo – mas isso realmente não significa nada mais do que “uma camada que não é entrada ou saída”. A rede acima tem apenas uma única camada oculta, mas algumas redes possuem múltiplas camadas ocultas. Por exemplo, a seguinte rede de quatro camadas tem duas camadas ocultas:
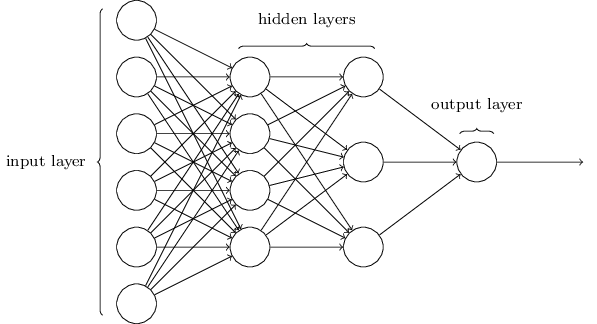
Tais redes de camadas múltiplas são chamados de Perceptrons Multicamadas ou MLPs (Multilayer Perceptrons), ou seja, uma rede neural formada por Perceptrons (embora na verdade seja uma rede de neurônios sigmóides, como veremos mais adiante).
O design das camadas de entrada e saída em uma rede geralmente é direto. Por exemplo, suponha que estamos tentando determinar se uma imagem manuscrita representa um “9” ou não. Uma maneira natural de projetar a rede é codificar as intensidades dos pixels da imagem nos neurônios de entrada. Se a imagem for uma imagem em escala de cinza 64 x 64, teríamos 64 × 64 = 4.096 neurônios de entrada, com as intensidades dimensionadas adequadamente entre 0 e 1. A camada de saída conterá apenas um único neurônio com valores inferiores a 0,5 indicando que “a imagem de entrada não é um 9” e valores maiores que 0,5 indicando que “a imagem de entrada é um 9”.
Embora o design das camadas de entrada e saída de uma rede neural seja frequentemente direto, pode haver bastante variação para o design das camadas ocultas. Em particular, não é possível resumir o processo de design das camadas ocultas com poucas regras simples. Em vez disso, pesquisadores de redes neurais desenvolveram muitas heurísticas de design para as camadas ocultas, que ajudam as pessoas a obter o comportamento que querem de suas redes. Conheceremos várias heurísticas de design desse tipo mais adiante ao longo dos próximos capítulos. O design das camadas ocultas é um dos pontos cruciais em modelos de Deep Learning.
Até agora, estamos discutindo redes neurais onde a saída de uma camada é usada como entrada para a próxima camada. Essas redes são chamadas de redes neurais feedforward. Isso significa que não há loops na rede – as informações sempre são alimentadas para a frente, nunca são enviadas de volta. Se tivéssemos loops, acabaríamos com situações em que a entrada para a função σ dependeria da saída. Isso seria difícil de entender e, portanto, não permitimos tais loops.
No entanto, existem outros modelos de redes neurais artificiais em que os circuitos de feedback são possíveis. Esses modelos são chamados de redes neurais recorrentes. A ideia nestes modelos é ter neurônios que disparem por algum período de tempo limitado. Disparar pode estimular outros neurônios, que podem disparar um pouco mais tarde, também por uma duração limitada. Isso faz com que ainda mais neurônios disparem e, ao longo do tempo, conseguimos uma cascata de disparos de neurônios. Loops não causam problemas em tal modelo, uma vez que a saída de um neurônio afeta apenas sua entrada em algum momento posterior, não instantaneamente.
Geralmente, as arquiteturas de redes neurais podem ser colocadas em 3 categorias específicas:
1- Redes Neurais Feed-Forward
Estes são o tipo mais comum de rede neural em aplicações práticas. A primeira camada é a entrada e a última camada é a saída. Se houver mais de uma camada oculta, nós as chamamos de redes neurais “profundas” (ou Deep Learning). Esses tipos de redes neurais calculam uma série de transformações que alteram as semelhanças entre os casos. As atividades dos neurônios em cada camada são uma função não-linear das atividades na camada anterior.
2- Redes Recorrentes
Estes tipos de redes neurais têm ciclos direcionados em seu grafo de conexão. Isso significa que às vezes você pode voltar para onde você começou seguindo as setas. Eles podem ter uma dinâmica complicada e isso pode torná-los muito difíceis de treinar. Entretanto, estes tipos são mais biologicamente realistas.
Atualmente, há muito interesse em encontrar formas eficientes de treinamento de redes recorrentes. As redes neurais recorrentes são uma maneira muito natural de modelar dados sequenciais. Eles são equivalentes a redes muito profundas com uma camada oculta por fatia de tempo; exceto que eles usam os mesmos pesos em cada fatia de tempo e recebem entrada em cada fatia. Eles têm a capacidade de lembrar informações em seu estado oculto por um longo período de tempo, mas é muito difícil treiná-las para usar esse potencial.
3- Redes Conectadas Simetricamente
Estas são como redes recorrentes, mas as conexões entre as unidades são simétricas (elas têm o mesmo peso em ambas as direções). As redes simétricas são muito mais fáceis de analisar do que as redes recorrentes. Elas também são mais restritas no que podem fazer porque obedecem a uma função de energia. As redes conectadas simetricamente sem unidades ocultas são chamadas de “Redes Hopfield”. As redes conectadas simetricamente com unidades ocultas são chamadas de “Máquinas de Boltzmann”.
Dentre estas 3 categorias, podemos listar as arquiteturas principais de redes neurais:
- Redes Multilayer Perceptron
- Redes Neurais Convolucionais
- Redes Neurais Recorrentes
- Long Short-Term Memory (LSTM)
- Redes de Hopfield
- Máquinas de Boltzmann
- Deep Belief Network
- Deep Auto-Encoders
- Generative Adversarial Network
- Deep Neural Network Capsules
- Transformadores
No próximo capítulo, daremos a você uma visão geral sobre cada uma dessas arquiteturas e ao longo dos capítulos seguintes, estudaremos todas elas. Cada umas dessas arquiteturas tem sido usada para resolver diferentes problemas e criar sistemas de Inteligência Artificial. Saber trabalhar com IA de forma eficiente, será determinante para seu futuro profissional.
Referências:
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition
Pattern Recognition and Machine Learning
Understanding Activation Functions in Neural Networks
Redes Neurais, princípios e práticas
Neural Networks and Deep Learning (alguns trechos extraídos e traduzidos com autorização do autor Michael Nielsen)