

Capítulo 67 – Algoritmo de Agente Baseado em IA com Reinforcement Learning – Parte 2
Vamos continuar nosso estudo sobre o Algoritmo de Agente Baseado em IA com Reinforcement Learning e compreender mais alguns detalhes importantes.
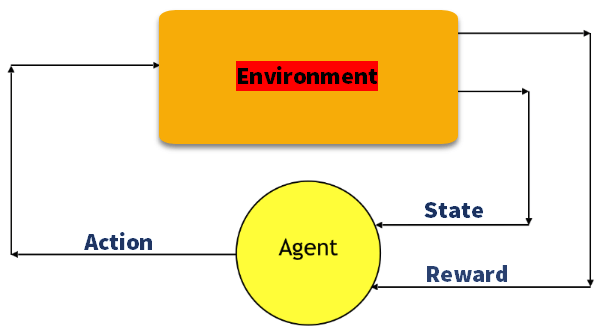
Aprendizado por Reforço (Reinforcement Learning) refere-se a um tipo de método de Aprendizado de Máquina (Machine Learning) no qual o agente recebe uma recompensa atrasada na próxima etapa para avaliar sua ação anterior. Recentemente, à medida que o algoritmo evolui com a combinação de redes neurais artificiais, ele é capaz de resolver tarefas mais complexas.
Embora exista um grande número de algoritmos de Aprendizado por Reforço, não parece haver uma comparação abrangente entre cada um deles. Quais algoritmos seriam aplicados a uma tarefa específica? Este capítulo tem como objetivo resolver esse problema discutindo brevemente a configuração da Aprendizado por Reforço e fornecendo uma introdução para alguns dos algoritmos conhecidos.
Componentes do Aprendizado Por Reforço
Vamos relembrar os componentes do Aprendizado Por Reforço:
Ação (A): Todos os movimentos possíveis que o agente pode executar
Estado (S): Situação atual retornada pelo ambiente.
Recompensa (R): Um retorno imediato é enviado do ambiente para avaliar a última ação.
Política (π): A estratégia que o agente emprega para determinar a próxima ação com base no estado atual.
Valor (V): O retorno esperado a longo prazo com desconto, em oposição à recompensa de curto prazo R. Vπ (s) é definido como o retorno esperado a longo prazo da atual política de desdobramento de estados π.
Valor Q ou Valor da Ação (Q): O valor Q é semelhante ao Valor, exceto pelo fato de ser necessário um parâmetro extra, a ação atual a. Qπ (s, a) refere-se ao retorno a longo prazo do estado atual s, realizando uma ação sob a política π.
Agora vamos compreender quais são os principais tipos de algoritmos usados em Aprendizado Por Reforço.
Model-free v.s. Model-based
O modelo representa a simulação da dinâmica do ambiente. Ou seja, o modelo aprende a probabilidade de transição T (s1 | (s0, a)) a partir do par de estado atual s0 e a ação a para o próximo estado s1. Se a probabilidade de transição for detectada com êxito, o agente saberá qual a probabilidade de entrar em um estado específico, dado o estado e a ação atuais.
No entanto, algoritmos baseados em modelo se tornam impraticáveis à medida que o espaço de estado e o espaço de ação aumentam (S * S * A, para uma configuração tabular).
Por outro lado, algoritmos sem modelo (Model-free) dependem de tentativa e erro para atualizar seu conhecimento. Como resultado, ele não requer espaço para armazenar toda a combinação de estados e ações. Em geral, os algoritmos desse tipo obtém resultados bem superiores, mas são mais complexos de programar.
On-policy v.s. Off-policy
Um agente on-policy aprende o valor com base em sua ação atual a derivada da política atual, enquanto sua contraparte off-policy o aprende com base na ação a* obtida de outra política. No Q-learning, essa política é a política gananciosa (falaremos mais sobre isso em Q-learning).
Abordagens Para Um Algoritmo de Aprendizado por Reforço
Existem três abordagens para implementar um algoritmo de Aprendizado por Reforço (Reinforcement Learning):
Baseado em Valor
Em um método de Aprendizado por Reforço baseado em valor, você deve tentar maximizar uma função de valor V (s). Nesse método, o agente espera um retorno a longo prazo dos estados atuais sob a política π.
Baseado em Políticas
Em um método de Aprendizado por Reforço baseado em política, você tenta criar uma política em que a ação executada em todos os estados ajude o agente a obter a recompensa máxima no futuro. Esse método tem dois sub-tipos:
- Determinístico: Para qualquer estado, a mesma ação é produzida pela política π.
- Estocástico: Toda ação tem uma certa probabilidade.
Baseado em Modelo
Neste método de Aprendizado por Reforço, você precisa criar um modelo virtual para cada ambiente. O agente aprende a atuar nesse ambiente específico.
Modelos de Aprendizagem de Reforço
Além escolher uma ou mais das abordagens acima mencionadas, precisamos definir o modelo de Aprendizado por Reforço. Existem três modelos de aprendizagem importantes amplamente usados em Reinforcement Learning:
Processo de Decisão de Markov
Nesse processo de aprendizagem do agente, os seguintes parâmetros são usados para obter uma solução:
- Conjunto de ações – A
- Conjunto de estados – S
- Recompensa – R
- Política – n
- Valor – V
A abordagem matemática para mapear uma solução no Aprendizado por Reforço é reconhecido como um Processo de Decisão de Markov (MDP).
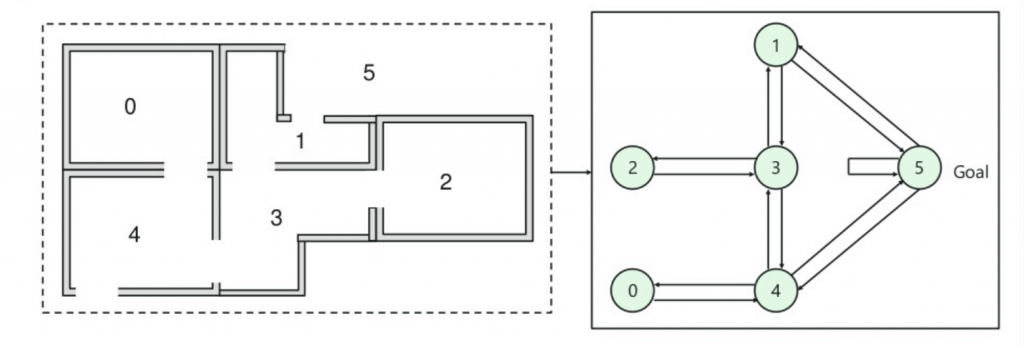
Q-Learning
Q-Learning é um método baseado em valor de fornecer informações para informar qual ação um agente deve executar.
Vamos entender esse método pelo seguinte exemplo simples, no qual o agente inteligente deve aprender a chegar à porta de saída (porta 5):
- Há cinco quartos em um prédio que são conectados por portas.
- Cada quarto é numerado de 0 a 4.
- A parte externa do edifício pode ser uma grande área externa (5).
- As portas número 1 e 4 levam ao prédio a partir da sala 5.
Em seguida, você precisa associar um valor de recompensa a cada porta:
- As portas que levam diretamente ao objetivo recebem uma recompensa de 100.
- Portas que não estão diretamente conectadas à sala de destino não oferecem recompensa.
- Como as portas são de mão dupla, duas setas são atribuídas para cada quarto.
- Cada seta na imagem acima contém um valor de recompensa instantâneo.
Explicação:
Nesta imagem, você pode ver que a sala representa um estado. O movimento do agente de uma sala para outra representa uma ação. Um estado é descrito como um nó, enquanto as setas mostram a ação.
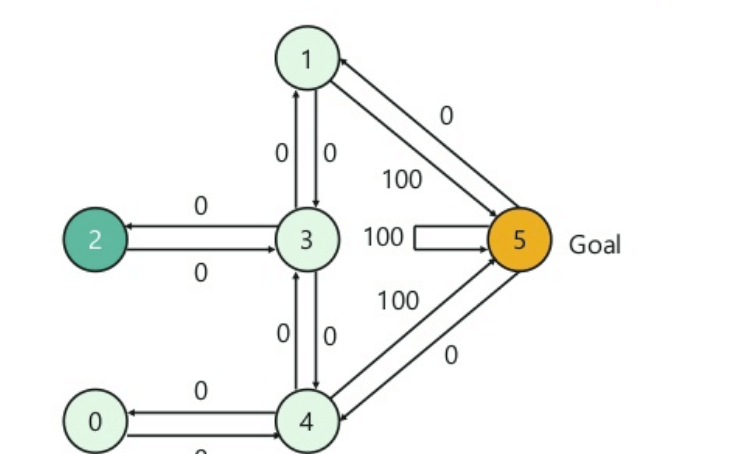
Por exemplo, um agente deve aprender a passar da porta 2 a porta 5. Aqui seriam as opções:
Estado inicial = estado 2
Estado 2-> estado 3
Estado 3 -> estado (2,1,4)
Estado 4-> estado (0,5,3)
Estado 1-> estado (5,3)
Estado 0-> estado 4
Como são várias possibilidades, nosso algoritmo deve recompensar aquelas que levam ao destino da forma mais rápida e penalizar aquelas que não levam. O agente então vai experimentando as possibilidades e criando uma tabela com o que traz recompensa e o que não traz. Se o aprendizado for bem sucedido o agente aprenderá o melhor conjunto de ações que leva ao destino.
Deep Q Network (DQN)
Embora o Q-learning seja um algoritmo muito poderoso, sua principal fraqueza é a falta de generalidade. Se você visualizar o Q-learning como números de atualização em uma matriz bidimensional (Espaço de Ação * Espaço de Estado), ele se parecerá com a programação dinâmica. Isso indica que, para os estados que o agente de Q-learning não viu antes, não tem ideia de qual ação executar. Em outras palavras, o agente de Q-learning não tem a capacidade de estimar valor para estados invisíveis. Para lidar com esse problema, o DQN se livra da matriz bidimensional introduzindo a Rede Neural Artificial Profunda (Deep Learning).
O DQN utiliza uma rede neural para estimar a função de valor Q. A entrada para a rede é a corrente, enquanto a saída é o valor Q correspondente a cada ação.
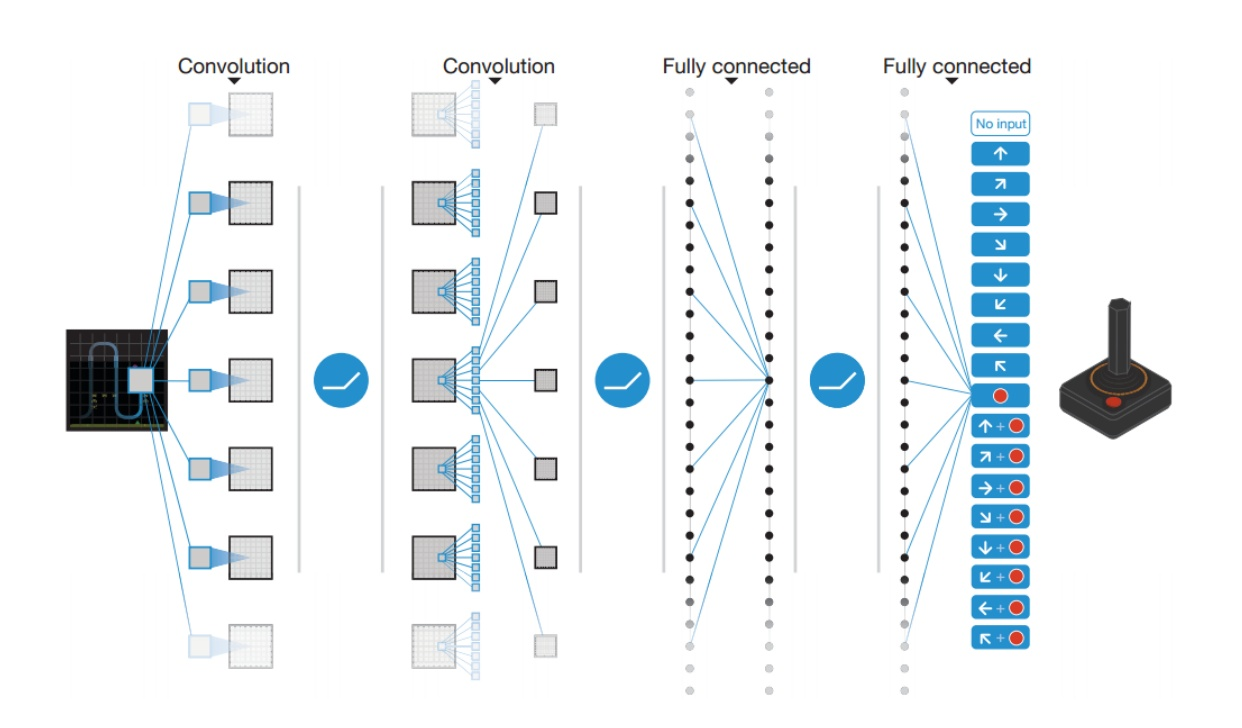
Em 2013, o DeepMind aplicou o DQN ao jogo Atari, conforme ilustrado na figura acima. A entrada é a imagem bruta da situação atual do jogo, que passa por várias camadas, incluindo a camada convolucional e a camada totalmente conectada. A saída é o valor Q para cada uma das ações que o agente pode executar.
Deep Deterministic Policy Gradient (DDPG)
Embora o DQN tenha alcançado grande sucesso em problemas dimensionais mais altos, como o jogo Atari, o espaço de ação ainda é discreto. No entanto, muitas tarefas de interesse, especialmente tarefas de controle físico, o espaço de ação é contínuo. Se você discretizar muito bem o espaço de ação, acabará tendo um espaço de ação muito grande. Por exemplo, suponha que o grau de sistema aleatório livre seja 10. Para cada grau, você divide o espaço em 4 partes. Você acaba tendo 4¹⁰ = 1048576 ações. Também é extremamente difícil convergir para um espaço de ação tão grande.
O DDPG conta com a arquitetura ator-crítico com dois elementos de mesmo nome, ator e crítico. Um ator é usado para ajustar o parâmetro ? para a função de política, ou seja, decidir a melhor ação para um estado específico.
O DDPG também empresta as ideias de repetição da experiência e separação da rede de destino, do DQN. Um problema do DDPG é que ele raramente realiza exploração de ações. Uma solução para isso é adicionar ruído no espaço de parâmetros ou no espaço de ação.
Como o objetivo deste livro é abordar principalmente Deep Learning, nos próximos capítulos estudaremos os algoritmos que empregam Deep Learning, o que chamamos de Deep Reinforcement Learning, talvez um dos métodos de IA mais avançados da atualidade. O método jé é estudado na DSA no curso de Inteligência Artificial Aplicada a Finanças, para otimização de portfólios financeiros e robôs investidores baseados em IA.
Estudar e aprender tem um efeito interessante: nos fazem mais humildes. Quando uma pessoa é muito arrogante, ela em geral é vazia em termos de conteúdo, pois arrogância é sinal de ignorância, falta de conhecimento. Quanto mais aprendemos, mais humildes ficamos, pois percebemos que o aprendizado é um ato contínuo e que temos muito, muito a aprender. Passamos a ver o mundo com outros olhos. Por isso estudar é transformador.
Até o próximo capítulo.
Referências:
Customizando Redes Neurais com Funções de Ativação Alternativas
A Beginner’s Guide to Deep Reinforcement Learning
Reinforcement Learning: What is, Algorithms, Applications, Example
What is reinforcement learning? The complete guide
Reinforcement Learning algorithms — an intuitive overview
Reinforcement Learning, Second Edition
Applications of Reinforcement Learning in Real World
Practical Recommendations for Gradient-Based Training of Deep Architectures
Gradient-Based Learning Applied to Document Recognition
Neural Networks & The Backpropagation Algorithm, Explained
Recurrent neural network based language model
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition