

Capítulo 51 – Arquitetura de Redes Neurais Long Short Term Memory (LSTM)
Estudamos as redes neurais recorrentes e suas limitações nos capítulos anteriores. Para superar alguns dos problemas das RNNs, podemos usar algumas de suas variações. Uma delas é chamada LSTM ou Long Short Term Memory, um tipo de rede neural recorrente, que é usada em diversos cenários de Processamento de Linguagem Natural. Neste capítulo estudaremos a Arquitetura de Redes Neurais Long Short Term Memory.
Precisamos de Memória
Os humanos não começam a pensar do zero a cada segundo. Ao ler este capítulo, você entende cada palavra com base em sua compreensão das palavras anteriores. Você não joga tudo fora e começa a pensar de novo a cada palavra que você lê. Seus pensamentos têm persistência.
As redes neurais tradicionais não podem fazer isso, o que dificulta sua aplicação para resolver diversos problemas. Por exemplo, imagine que você queira classificar o tipo de evento que está acontecendo em todos os pontos de um filme. Não está claro como uma rede neural tradicional poderia usar o aprendizado sobre eventos anteriores no filme para informar os posteriores.
Redes neurais recorrentes resolvem esse problema. São redes com loops, permitindo que as informações persistam.
Esses laços fazem com que as redes neurais recorrentes pareçam misteriosas. No entanto, se você pensar um pouco mais, perceberá que não são tão diferentes de uma rede neural normal. Uma rede neural recorrente pode ser imaginada como múltiplas cópias da mesma rede, cada uma passando uma mensagem a um sucessor. Considere o que acontece se desenrolarmos o loop:
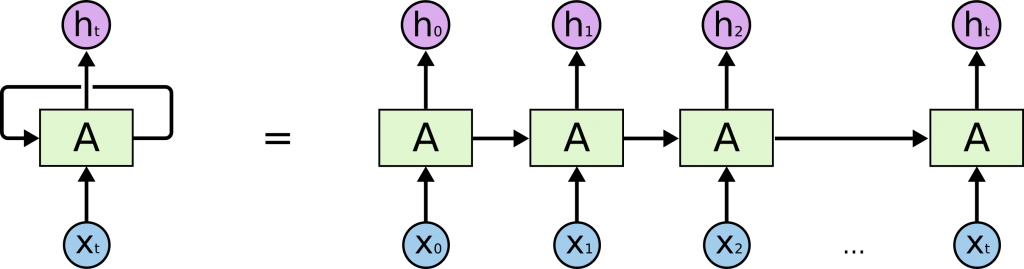
Essa natureza de cadeia revela que redes neurais recorrentes estão intimamente relacionadas a sequências e listas, uma arquitetura natural da rede neural a ser usada para esses dados.
Nos últimos anos, tem havido um incrível sucesso ao aplicar as RNNs a uma variedade de problemas: reconhecimento de fala, modelagem de idiomas, tradução, legendas de imagens… A lista continua. Deixarei a discussão sobre os incríveis feitos que podemos alcançar com as RNNs com o excelente post de Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks.
Entretanto, boa parte do sucesso das RNNs se deve a uma de suas variações, as LSTMs, um tipo muito especial de rede neural recorrente que funciona, para muitas tarefas, muito melhor do que a versão padrão. Quase todos os resultados empolgantes baseados em redes neurais recorrentes são alcançados com LSTMs. Vamos então compreender o que torna as LSTMs tão especiais.
Arquitetura da LSTM
A LSTM é uma arquitetura de rede neural recorrente (RNN) que “lembra” valores em intervalos arbitrários. A LSTM é bem adequada para classificar, processar e prever séries temporais com intervalos de tempo de duração desconhecida. A insensibilidade relativa ao comprimento do gap dá uma vantagem à LSTM em relação a RNNs tradicionais (também chamadas “vanilla”), Modelos Ocultos de Markov (MOM) e outros métodos de aprendizado de sequências.
A estrutura de uma RNN é muito semelhante ao Modelo Oculto de Markov. No entanto, a principal diferença é como os parâmetros são calculados e construídos. Uma das vantagens da LSTM é a insensibilidade ao comprimento do gap. RNN e MOM dependem do estado oculto antes da emissão / sequência. Se quisermos prever a sequência após 1.000 intervalos em vez de 10, o modelo esqueceu o ponto de partida até então. Mas um modelo LSTM é capaz de “lembrar” por conta de sua estrutura de células, o diferencial da arquitetura LSTM.
A LSTM possui uma estrutura em cadeia que contém quatro redes neurais e diferentes blocos de memória chamados células.
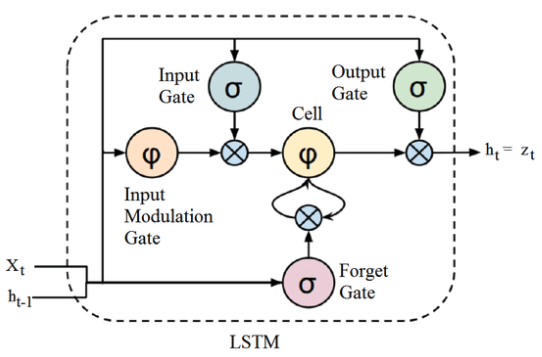
A informação é retida pelas células e as manipulações de memória são feitas pelos portões (gates). Existem três portões:
Forget Gate: As informações que não são mais úteis no estado da célula são removidas com o forget gate. Duas entradas: x_t (entrada no momento específico) e h_t-1 (saída de célula anterior) são alimentadas ao gate e multiplicadas por matrizes de peso, seguidas pela adição do bias. O resultante é passado por uma função de ativação que fornece uma saída binária. Se para um determinado estado de célula a saída for 0, a informação é esquecida e para a saída 1, a informação é retida para uso futuro.
Input Gate: A adição de informações úteis ao estado da célula é feita pelo input gate. Primeiro, a informação é regulada usando a função sigmoide que filtra os valores a serem lembrados de forma similar ao forget gate usando as entradas h_t-1 e x_t. Então, um vetor é criado usando a função tanh que dá saída de -1 a +1, que contém todos os valores possíveis de h_t-1 e x_t. Os valores do vetor e os valores regulados são multiplicados para obter as informações úteis
Output Gate: A tarefa de extrair informações úteis do estado da célula atual para ser apresentadas como uma saída é feita pelo output gate. Primeiro, um vetor é gerado aplicando a função tanh na célula. Então, a informação é regulada usando a função sigmóide que filtra os valores a serem lembrados usando as entradas h_t-1 e x_t. Os valores do vetor e os valores regulados são multiplicados para serem enviados como uma saída e entrada para a próxima célula.
A célula RNN recebe duas entradas, a saída do último estado oculto e a observação no tempo = t. Além do estado oculto, não há informações sobre o passado para se lembrar. A memória de longo prazo é geralmente chamada de estado da célula. As setas em loop indicam a natureza recursiva da célula. Isso permite que as informações dos intervalos anteriores sejam armazenadas na célula LSTM. O estado da célula é modificado pelo forget gate colocado abaixo do estado da célula e também ajustado pela porta de modulação de entrada. Da equação, o estado da célula anterior esquece, multiplica-se com a porta do esquecimento e adiciona novas informações através da saída das portas de entrada.
Algumas das famosas aplicações das LSTMs incluem:
- Modelagem de Linguagem
- Tradução de Idiomas
- Legendas em Imagens
- Geração de Texto
- Chatbots
Continuamos no próximo capítulo!
Referências:
Formação Engenheiro de Inteligência Artificial
Customizando Redes Neurais com Funções de Ativação Alternativas
A Recursive Recurrent Neural Network for Statistical Machine Translation
Sequence to Sequence Learning with Neural Networks
Recurrent Neural Networks Cheatsheet
On the difficulty of training recurrent neural networks
A Beginner’s Guide to LSTMs and Recurrent Neural Networks
Long Short-Term Memory (LSTM): Concept
Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs
Recurrent Neural Networks Tutorial, Part 3 – Backpropagation Through Time and Vanishing Gradients
Practical Recommendations for Gradient-Based Training of Deep Architectures
Gradient-Based Learning Applied to Document Recognition
Neural Networks & The Backpropagation Algorithm, Explained
Neural Networks and Deep Learning
Recurrent neural network based language model
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition