

Capítulo 41 – Campos Receptivos Locais em Redes Neurais Convolucionais
Vamos estudar em detalhes a partir de agora as Redes Neurais Convolucionais, uma das principais arquiteturas de Deep Learning, amplamente usada em Visão Computacional. E começaremos compreendendo o que são os Campos Receptivos Locais. Mas antes, afinal, o que é Visão Computacional, amplamente usada em aplicações de Inteligência Artificial?
O Que é Visão Computacional?
Imagine a seguinte situação: você está em uma sala com mais duas pessoas. Uma delas arremessa uma bola e você a pega com as mãos. Nada poderia ser mais simples, certo?
Errado. Na verdade, este é um dos processos mais complexos que já tentamos compreender, ou seja, como o cérebro processa a visão de modo que sabemos exatamente o que é uma bola e quando ela está vindo em nossa direção? E ensinar uma máquina que seja capaz de ver da mesma forma que nós seres humanos é uma tarefa realmente difícil, não só porque é difícil fazer computadores executarem um cálculo matemático que reproduza a visão humana, mas porque não estamos inteiramente certos de como o processo da visão realmente funciona.
Primeiro vamos descrever de forma sucinta e aproximada como ocorre o processo de visão no caso do arremesso da bola: a imagem da esfera passa através de seu olho e chega a sua retina, que faz alguma análise elementar e envia o resultado ao cérebro, onde o córtex visual analisa mais profundamente a imagem. Em seguida, ele envia para o resto do córtex, que compara a tudo o que já sabe, classifica os objetos e dimensões e, finalmente, decide sobre algo a fazer: levantar a mão e pegar a bola (tendo previsto o seu caminho). Isso ocorre em uma pequena fração de segundo, com quase nenhum esforço consciente e quase nunca falha. Assim, recriar a visão humana não é apenas um problema difícil, é um conjunto deles, cada um dos quais depende do outro.
A Visão Computacional é o processo de modelagem e replicação da visão humana usando software e hardware. A Visão Computacional é uma disciplina que estuda como reconstruir, interromper e compreender uma cena 3d a partir de suas imagens 2d em termos das propriedades da estrutura presente na cena.
Visão Computacional e reconhecimento de imagem são termos frequentemente usados como sinônimos, mas o primeiro abrange mais do que apenas analisar imagens. Isso porque, mesmo para os seres humanos, “ver” também envolve a percepção em muitas outras frentes, juntamente com uma série de análises. Cada ser humano usa cerca de dois terços do seu cérebro para o processamento visual, por isso não é nenhuma surpresa que os computadores precisariam usar mais do que apenas o reconhecimento de imagem para obter sua visão de forma correta.
O reconhecimento de imagens em si – a análise de pixel e padrão de imagens – é uma parte integrante do processo de Visão Computacional que envolve tudo, desde reconhecimento de objetos e caracteres até análise de texto e sentimento. O reconhecimento de imagem de hoje, ainda na maior parte, apenas identifica objetos básicos como “uma banana ou uma bicicleta em uma imagem.” Mesmo crianças podem fazer isso, mas o potencial da Visão Computacional é sobre-humano: ser capaz de ver claramente no escuro, através de paredes, em longas distâncias e processar todos esses dados rapidamente e em volume maciço.
Já a Visão Computacional em seu sentido mais pleno está sendo usada na vida cotidiana e nos negócios para conduzir todos os tipos de tarefas, incluindo identificar doenças médicas em raios-x, identificar produtos e onde comprá-los, anúncios dentro de imagens editoriais, entre outros.
A Visão Computacional pode ser usada para digitalizar plataformas de mídia social a fim de encontrar imagens relevantes que não podem ser descobertas por meio de pesquisas tradicionais. A tecnologia é complexa e, assim como todas as tarefas acima mencionadas, requer mais do que apenas reconhecimento de imagem, mas também análise semântica de grandes conjuntos de dados. E a Visão Computacional é a principal técnica por trás dos veículos autônomos, que devem mudar completamente o mundo como o conhecemos.
Ninguém nunca disse que isso seria fácil. Exceto, talvez, Marvin Minsky, pioneiro da Inteligência Artificial, que, em 1966, instruía um estudante de pós-graduação a “conectar uma câmera a um computador e fazer com que descrevesse o que vê”. Mas a verdade é que 50 anos depois, ainda estamos trabalhando nisso, porém agora há uma diferença (ou duas talvez): temos Big Data e Processamento Paralelo em GPU’s. E acredite. Isso está realmente fazendo a diferença.
As Redes Neurais Convolucionais formam uma das arquiteturas de Deep Learning mais amplamente usada em tarefas de Visão Computacional e reconhecimento de imagens e a partir de agora vamos compreender porque.
Campos Receptivos Locais
Nas camadas totalmente conectadas mostradas no capítulo anterior, as entradas foram representadas como uma linha vertical de neurônios. Ou seja, convertemos uma imagem 28 x 28 (que é uma matriz) em um vetor de apenas uma dimensão (falaremos sobre isso mais adiante). Mas para compreender o que é um campo receptivo local, vamos considerar a imagem de seu formato padrão de 28x 28 (tamanho das imagens no dataset MNIST). Em uma imagem, cada pixel é um valor numérico que representa a intensidade de cor de acordo com a escala de cor utilizada, como RGB (Red – Green – Blue), por exemplo, ou apenas intensidade em escala de cinza para imagens em preto e branco.

Como de costume, vamos conectar os pixels de entrada a uma camada de neurônios ocultos. Mas não vamos conectar todos os pixels de entrada a cada neurônio oculto. Em vez disso, apenas fazemos conexões em regiões pequenas e localizadas da imagem de entrada.
Para ser mais preciso, cada neurônio na primeira camada oculta será conectado a uma pequena região dos neurônios de entrada, digamos, por exemplo, uma região de 5 × 5, correspondendo a 25 pixels de entrada. Assim, para um neurônio oculto em particular, podemos ter conexões que se parecem com isso:
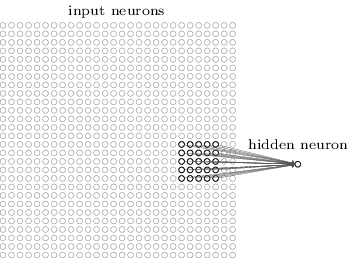
Essa região na imagem de entrada é chamada de campo receptivo local para o neurônio oculto. É uma pequena janela nos pixels de entrada. Cada conexão aprende um peso e o neurônio oculto também aprende um viés (bias) geral. Você pode pensar nesse neurônio oculto particular como aprendendo a analisar seu campo receptivo local específico.
Em seguida, deslizamos o campo receptivo local por toda a imagem de entrada. Para cada campo receptivo local, existe um neurônio oculto diferente na primeira camada oculta. Para ilustrar isso concretamente, vamos começar com um campo receptivo local no canto superior esquerdo:

Então, deslizamos o campo receptivo local por um pixel para a direita (ou seja, por um neurônio), para conectar a um segundo neurônio oculto:

E assim por diante, construindo a primeira camada oculta. Observe que, se tivermos uma imagem de entrada 28 × 28 e campos receptivos locais 5 × 5, haverá 24 × 24 neurônios na camada oculta. Isso ocorre porque só podemos mover o campo receptivo local 23 neurônios para o lado (ou 23 neurônios para baixo), antes de colidir com o lado direito (ou inferior) da imagem de entrada.
Mostramos o campo receptivo local sendo movido por um pixel por vez. Na verdade, às vezes, um comprimento de passada diferente é usado. Por exemplo, podemos mover o campo receptivo local 2 pixels para a direita (ou para baixo), caso em que diríamos que um comprimento de passada de 2 é usado. Esse é um dos hyperparâmetros de uma rede neural convolucional, chamado stride length. No exemplo acima usado um stride length de 1, mas vale a pena saber que as pessoas às vezes experimentam comprimentos de passada diferentes.
Como foi feito nos capítulos anteriores, se estivermos interessados em testar comprimentos de passada diferentes, podemos usar os dados de validação para escolher o comprimento da passada que oferece o melhor desempenho. A mesma abordagem também pode ser usada para escolher o tamanho do campo receptivo local – não há, é claro, nada de especial sobre o uso de um campo receptivo local 5 × 5. Em geral, campos receptivos locais maiores tendem a ser úteis quando as imagens de entrada são significativamente maiores que as imagens MNIST de 28 × 28 pixels.
Eu já disse que cada neurônio oculto tem um viés e pesos 5 × 5 conectados ao seu campo receptivo local. O que eu ainda não mencionei é que vamos usar os mesmos pesos e vieses para cada um dos 24 × 24 neurônios ocultos. Quer saber como faremos isso matematicamente? Então não perca o próximo capítulo!
Referências:
Análise de Imagens com Inteligência Artificial
Don’t Decay the Learning Rate, Increase the Batch Size
Practical Recommendations for Gradient-Based Training of Deep Architectures
Gradient-Based Learning Applied to Document Recognition
A Comprehensive Guide to Convolutional Neural Networks
Neural Networks & The Backpropagation Algorithm, Explained
Neural Networks and Deep Learning
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition