

Capítulo 90 – Como Funcionam os Transformadores em Processamento de Linguagem Natural – Parte 5
Vamos prosseguir estudando os transformadores. Este capítulo considera que você leu os capítulos anteriores.
Vamos começar esta capítulo com um resumo do Transformer. Para processar uma frase, precisamos destes 3 passos:
1- Embeddings de palavras da sentença de entrada são computados simultaneamente.
2- Codificações posicionais são então aplicadas a cada Embeddings, resultando em vetores de palavras que também incluem informações posicionais.
3- Os vetores de palavras são passados para o primeiro bloco do codificador.
Cada bloco consiste nas seguintes camadas na mesma ordem:
- Uma camada de autoatenção de várias cabeças para encontrar correlações entre cada palavra.
- Uma camada de normalização.
- Uma conexão residual em torno das duas subcamadas anteriores.
- Uma camada linear.
- Uma segunda camada de normalização.
- Uma segunda conexão residual.
Observe que o bloco acima pode ser replicado várias vezes para formar o Encoder. No papel original, o codificador é composto por 6 blocos como na imagem abaixo.
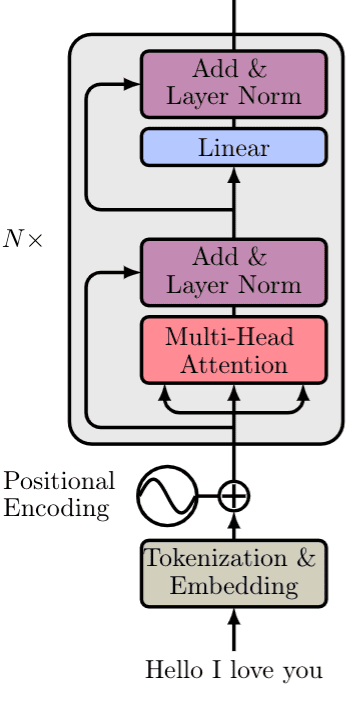
Vamos ver o que pode ser diferente na parte do decodificador.
O decodificador consiste em todos os componentes acima mencionados mais dois novos. Como antes:
1- A sequência de saída é alimentada em sua totalidade e os embeddings de palavras são calculados.
2- A codificação posicional é novamente aplicada.
3- E os vetores são passados para o primeiro bloco Decoder
Cada bloco decodificador inclui:
- Uma camada de autoatenção de várias cabeças.
- Uma camada de normalização seguida por uma conexão residual.
- Uma nova camada de atenção de várias cabeças (conhecida como atenção Encoder-Decoder).
- Uma segunda camada de normalização e uma conexão residual.
- Uma camada linear e uma terceira conexão residual.
O bloco decodificador aparece novamente 6 vezes. A saída final é transformada através de uma camada linear final e as probabilidades de saída são calculadas com a função softmax padrão. A imagem abaixo traz um resumo.
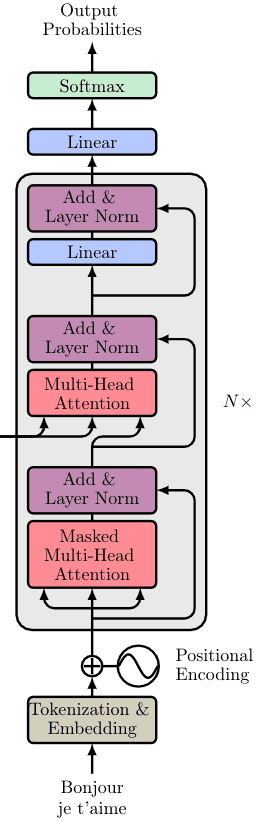
As probabilidades de saída predizem o próximo token na sentença de saída. Como? Em essência, atribuímos uma probabilidade a cada palavra e simplesmente mantemos aquela com a maior pontuação.
Para colocar as coisas em perspectiva, o modelo original foi treinado no conjunto de dados inglês-francês do WMT 2014, composto por 36 milhões de frases e 32.000 tokens.
Embora a maioria dos conceitos do decodificador já seja familiar, há mais dois que precisamos discutir. Vamos começar com a camada de autoatenção de várias cabeças mascaradas.
Masked Multi-head Attention
Caso você não tenha percebido, na etapa de decodificação, prevemos uma palavra (token) após a outra. Em problemas de PLN como a tradução automática, a previsão sequencial de tokens é inevitável. Como resultado, a camada de autoatenção precisa ser modificada para considerar apenas a sentença de saída gerada até o momento.
Em nosso exemplo de tradução, a entrada do decodificador na terceira passagem será “Bonjour”, “je” … …”.
Como você pode ver, a diferença aqui é que não conhecemos a frase inteira porque ela ainda não foi produzida. É por isso que precisamos desconsiderar as palavras desconhecidas. Caso contrário, o modelo apenas copiaria a próxima palavra! Para conseguir isso, mascaramos os próximos embeddings de palavras.
Matematicamente temos:
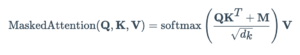
onde a matriz M (máscara) consiste em zeros e -inf.
Zeros se tornarão uns com o exponencial enquanto infinitos se tornarão zeros.
Isso efetivamente tem o mesmo efeito que remover a conexão correspondente. Os princípios restantes são exatamente os mesmos que a atenção do codificador. E mais uma vez, podemos implementá-los em paralelo para acelerar os cálculos.
Obviamente, a máscara mudará para cada novo token que computarmos.
Atenção Codificador-Decodificador: Onde a Mágica Acontece
Na verdade, é aqui que o decodificador processa a representação codificada. A matriz de atenção gerada pelo codificador é passada para outra camada de atenção juntamente com o resultado do bloco de atenção Masked Multi-head anterior.
A intuição por trás da camada de atenção codificador-decodificador é combinar a sentença de entrada e saída. A saída do codificador encapsula a embedding final da sentença de entrada. É como nosso banco de dados. Portanto, usaremos a saída do codificador para produzir as matrizes Key e Value. Por outro lado, a saída do bloco de atenção Masked Multi-head contém a nova sentença gerada até agora e é representada como a matriz de consulta na camada de atenção. Novamente, é a “pesquisa” no banco de dados.
Ele acabará por determinar o quão relacionado cada palavra em inglês está em relação às palavras em francês. É essencialmente aí que está acontecendo o mapeamento entre inglês e francês.
Observe que a saída do último bloco do codificador será utilizada em cada bloco do decodificador.
Por Que os Transformadores Funcionam Tão Bem?
1- Representações distribuídas e independentes em cada bloco: Cada bloco transformador tem 8 representações contextualizadas. Intuitivamente, você pode pensar nisso como os vários mapas de recursos de uma camada de convolução que capturam diferentes recursos da imagem. A diferença com as convoluções é que aqui temos múltiplas vistas (reprojeções lineares) para outros espaços. Obviamente, isso é possível ao representar inicialmente palavras como vetores em um espaço euclidiano (e não como símbolos discretos).
2- O significado depende muito do contexto: é exatamente disso que se trata a autoatenção! Associamos relações entre a representação de palavras expressa pelos pesos de atenção. Não há noção de localidade, pois naturalmente deixamos o modelo fazer associações globais.
3- Vários blocos de codificador e decodificador: Com mais camadas, o modelo faz representações mais abstratas. Semelhante ao empilhamento de blocos recorrentes ou de convolução, podemos empilhar vários blocos de transformadores. O primeiro bloco associa pares palavra-vetor, o segundo pares de pares, o terceiro de pares de pares de pares e assim por diante. Em paralelo, as múltiplas cabeças se concentram em diferentes segmentos dos pares. Isso é análogo ao campo receptivo, mas em termos de pares de representações distribuídas.
4- Combinação de informações de alto e baixo nível: com conexões de salto, é claro! Eles permitem que a compreensão de cima para baixo flua de volta com os vários caminhos de gradiente que fluem para trás.
Autoatenção x Camadas Lineares x Convoluções
Qual é a diferença entre atenção e uma camada de feed forward em um modelo padrão de rede neural? As camadas lineares não fazem exatamente as mesmas operações para um vetor de entrada como atenção?
Boa pergunta! A resposta é não se você se aprofundar nos conceitos.
Você vê que os valores dos pesos de autoatenção são calculados em tempo real. Eles são pesos dinâmicos dependentes de dados porque mudam dinamicamente em resposta aos dados (pesos rápidos).
Por exemplo, cada palavra na sequência traduzida (Bonjour, je t’aime) atenderá de forma diferente em relação à entrada.
Por outro lado, os pesos de uma camada feedforward (linear) mudam muito lentamente com a descida do gradiente estocástico. Em convoluções, restringimos ainda mais o peso (lento) para ter um tamanho fixo, ou seja, o tamanho do kernel.
Conclusão
Ufa! Compreendeu agora porque a Inteligência Artificial é algo tão incrível? Usamos a Matemática via programação de computadores para fazer a mágica acontecer. E isso está revolucionando o mundo como conhecemos!
O Transformer é um conceito mais avançado e nosso objetivo aqui foi trazer uma visão geral. Concluímos aqui a parte sobre Transformer.
Mas temos ainda mais 10 capítulos pela frente para concluir o Deep Learning Book. Que tal uma revisão completa e gratuita sobre Machine Learning para encerrar este livro? É o que teremos nos 10 capítulos finais. Não perca.
Referências:
Deep Learning Para Aplicações de IA com PyTorch e Lightning
Processamento de Linguagem Natural
Understanding Attention In Deep Learning
How Transformers work in deep learning and NLP: an intuitive introduction