

Capítulo 13 – Construindo Uma Rede Neural Com Linguagem Python
Ok. Chegou a hora. Vamos escrever um programa em linguagem Python que aprenda como reconhecer dígitos manuscritos, usando Stochastic Gradient Descent e o dataset de treinamento MNIST. Se você chegou até aqui sem ler os capítulos anteriores, então pare imediatamente, leia os últimos 12 capítulos e depois volte aqui! Não tenha pressa! Não existe atalho para o aprendizado!
******************************** Atenção ********************************
Este capítulo considera que você já tem o interpretador Python instalado no seu computador, seja ele com sistema operacional Windows, MacOS ou Linux. Recomendamos que você instale o Anaconda e que já possua conhecimentos em linguagem Python. Se esse não for seu caso, antes de ler este capítulo e executar os exemplos aqui fornecidos, acesse o curso gratuito Fundamentos de Linguagem Python Para Análise de Dados e Data Science.
Usaremos Python 3 e você deve construir os scripts no seu computador. Vamos começar!
*************************************************************************
Quando descrevemos o dataset MNIST anteriormente, dissemos que ele estava dividido em 60.000 imagens de treinamento e 10.000 imagens de teste. Essa é a descrição oficial do MNIST. Mas vamos dividir os dados de forma um pouco diferente. Deixaremos as imagens de teste como está, mas dividiremos o conjunto de treinamento MNIST de 60.000 imagens em duas partes: um conjunto de 50.000 imagens, que usaremos para treinar nossa rede neural e um conjunto separado de validação de 10.000 imagens. Não utilizaremos os dados de validação neste capítulo, porém mais tarde, aqui mesmo no livro, usaremos este dataset quando estivermos configurando certos hiperparâmetros da rede neural, como a taxa de aprendizado por exemplo. Embora os dados de validação não façam parte da especificação MNIST original, muitas pessoas usam o MNIST desta forma e o uso de dados de validação é comum em redes neurais. Quando eu me referir aos “dados de treinamento MNIST” de agora em diante, vou me referir ao nosso conjunto de dados de 50.000 imagens, e não ao conjunto de dados de 60.000 imagens. Fique atento!
Além dos dados MNIST, também precisamos de uma biblioteca Python chamada Numpy, para álgebra linear. Se você instalou o Anaconda, não precisa se preocupar, pois o Numpy já está instalado. Caso contrário, será necessário fazer a instalação do pacote.
Mas antes de carregar e dividir os dados, vamos compreender os principais recursos do nosso código para construção de uma rede neural. A peça central é uma classe chamada Network, que usamos para representar uma rede neural. Abaixo a classe Network e seu construtor:

Neste código, o parâmetro sizes contêm o número de neurônios nas respectivas camadas, sendo um objeto do tipo lista em Python. Então, por exemplo, se queremos criar um objeto da classe Network com 2 neurônios na primeira camada, 3 neurônios na segunda camada e 1 neurônio na camada final, aqui está o código que usamos para instanciar um objeto da classe Network::
rede1 = Network([2, 3, 1])
Os bias e pesos no objeto rede1 são todos inicializados aleatoriamente, usando a função Numpy np.random.randn para gerar distribuições gaussianas com 0 de média e desvio padrão 1. Esta inicialização aleatória dá ao nosso algoritmo de descida do gradiente estocástico um local para começar. Em capítulos posteriores, encontraremos melhores maneiras de inicializar os pesos e os bias. Observe que o código de inicialização de rede assume que a primeira camada de neurônios é uma camada de entrada e omite a definição de quaisquer bias para esses neurônios, uma vez que os bias são usados apenas para calcular as saídas de camadas posteriores.
Observe também que os bias e pesos são armazenados como listas de matrizes Numpy. Assim, por exemplo, rede1.weights[1] é uma matriz Numpy armazenando os pesos conectando a segunda e terceira camadas de neurônios. (Não é a primeira e segunda camadas, uma vez que a indexação da lista em Python começa em 0.) Uma vez que rede1.weights[1] é bastante detalhado, vamos apenas indicar essa matriz w. É uma matriz tal que wjk é o peso para a conexão entre o neurônio kth na segunda camada e o neurônio jth na terceira camada. Essa ordenação dos índices j e k pode parecer estranha – certamente teria mais sentido trocar os índices j e k? A grande vantagem de usar essa ordenação é que isso significa que o vetor de ativações da terceira camada de neurônios é:
![]()
Equação 1
Onde, a é o vetor de ativações da segunda camada de neurônios. Para obter um a’ multiplicamos a pela matriz de peso w, e adicionamos o vetor b com os bias (se você leu os capítulos anteriores, isso não deve ser novidade agora). Em seguida, aplicamos a função σ de forma elementar a cada entrada no vetor wa + b. (Isto é chamado de vetorizar a função σ.)
Com tudo isso em mente, é fácil escrever código que computa a saída de uma instância de rede. Começamos definindo a função sigmoide:
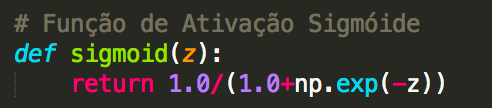
Observe que quando a entrada z é um vetor ou uma matriz Numpy, Numpy aplica automaticamente a função sigmoid elementwise, ou seja, na forma vetorizada.
Em seguida, adicionamos um método feedforward à classe Network, que, dada a entrada a para a rede, retorna a saída corresponente. Basicamente o método feedforward aplica a Equação 1 mostrada acima, para cada camada:

A principal atividade que queremos que nossos objetos da classe Network façam é aprender. Para esse fim, criaremos um método SGD (Stochastic Gradient Descent). Aqui está o código. É um pouco misterioso em alguns lugares, mas vamos explicar em detalhes mais abaixo:
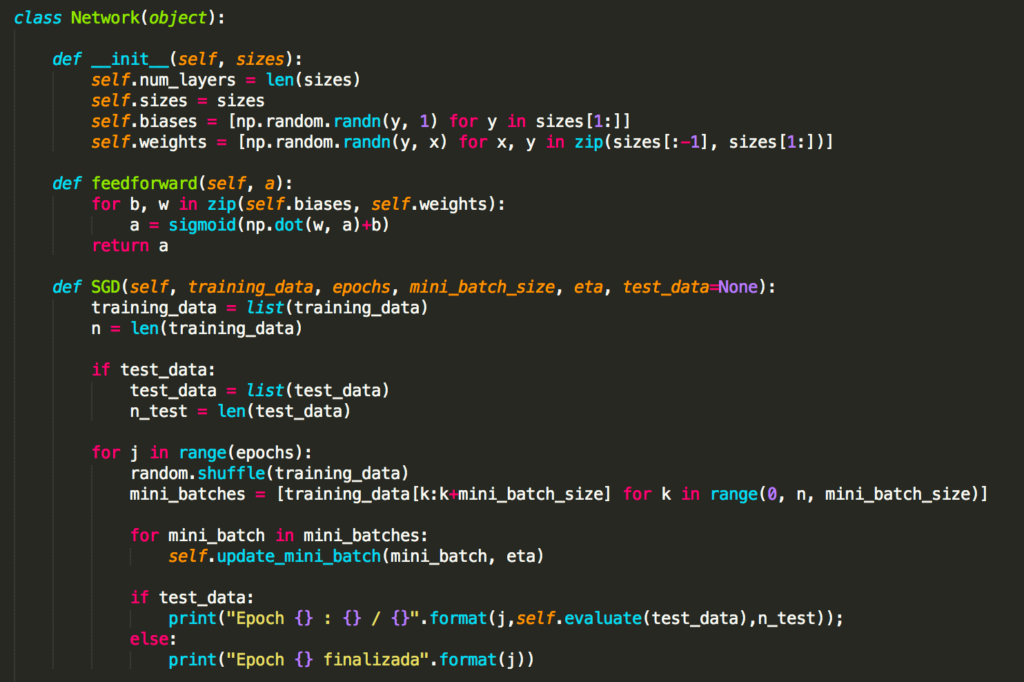
O training_data é uma lista de tuplas (x, y) que representam as entradas de treinamento e as correspondentes saídas desejadas. As variáveis epochs e mini_batch_size são o que você esperaria – o número de épocas para treinar e o tamanho dos mini-lotes a serem usados durante a amostragem, enquanto eta é a taxa de aprendizagem, η. Se o argumento opcional test_data for fornecido, o programa avaliará a rede após cada período de treinamento e imprimirá progresso parcial. Isso é útil para rastrear o progresso, mas retarda substancialmente as coisas.
O código funciona da seguinte forma. Em cada época, ele começa arrastando aleatoriamente os dados de treinamento e, em seguida, particiona-os em mini-lotes de tamanho apropriado. Esta é uma maneira fácil de amostragem aleatória dos dados de treinamento. Então, para cada mini_batch, aplicamos um único passo de descida do gradiente. Isso é feito pelo código self.update_mini_batch (mini_batch, eta), que atualiza os pesos e os bias da rede de acordo com uma única iteração de descida de gradiente, usando apenas os dados de treinamento em mini_batch. Aqui está o código para o método update_mini_batch:
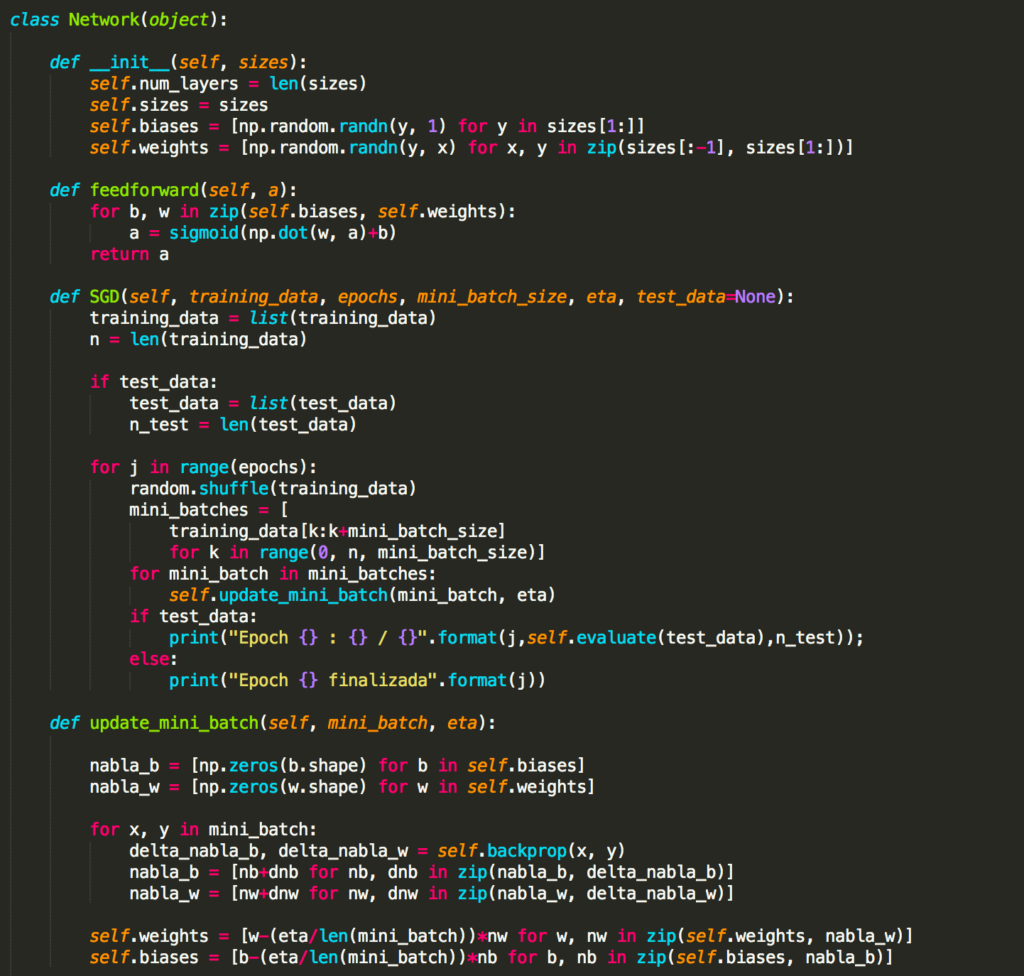
A maior parte do trabalho é feita pela linha delta_nabla_b, delta_nabla_w = self.backprop (x, y). Isso invoca algo chamado algoritmo de backpropagation, que é uma maneira rápida de calcular o gradiente da função de custo. Portanto, update_mini_batch funciona simplesmente calculando esses gradientes para cada exemplo de treinamento no mini_batch e, em seguida, atualizando self.weights e self.biases adequadamente.
Abaixo você encontra o código para self.backprop, mas não estudaremos ele agora. Estudaremos em detalhes como funciona o backpropagation no próximo capítulo, incluindo o código para self.backprop. Por hora, basta assumir que ele se comporta conforme indicado, retornando o gradiente apropriado para o custo associado ao exemplo de treinamento x.
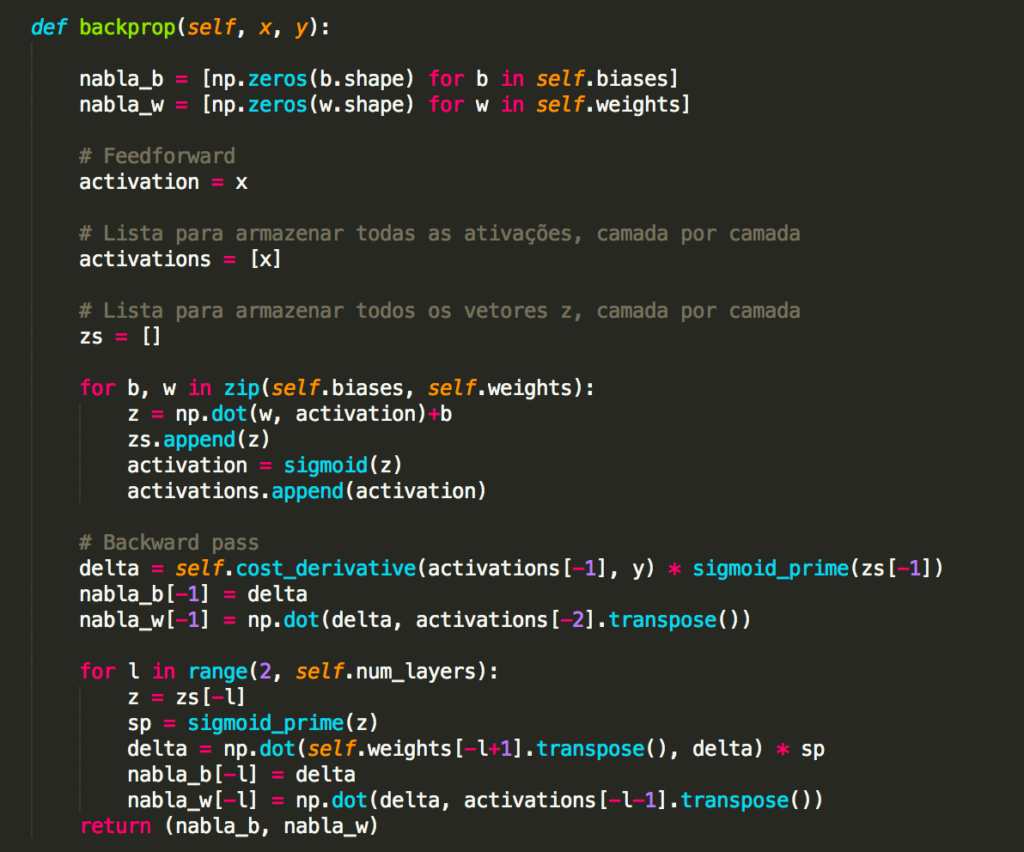
Além do self.backprop, o programa é auto-explicativo – todo o levantamento pesado é feito em self.SGD e self.update_mini_batch, que já discutimos. O método self.backprop faz uso de algumas funções extras para ajudar no cálculo do gradiente, nomeadamente sigmoid_prime, que calcula a derivada da função σ e self.cost_derivative.
A classe Network é em essência nosso algoritmo de rede neural. A partir dela criamos uma instância (como rede1), alimentamos com os dados de treinamento e realizamos o treinamento. Avaliamos então a performance da rede com dados de teste e repetimos todo o processo até alcançar o nível de acurácia desejado em nosso projeto. Quando o modelo final estiver pronto, usamos para realizar as previsões para as quais o modelo foi criado, apresentando a ele novos conjuntos de dados e extraindo as previsões. Perceba que este é um algoritmo de rede neural bem simples, mas que permite compreender como funcionam as redes neurais e mais tarde, aqui mesmo no livro, as redes neurais profundas ou Deep Learning.
No próximo capítulo vamos continuar trabalhando com este algoritmo e compreender como funciona o Backpropagation. Na sequência, vamos carregar os dados, treinar e testar nossa rede neural e então usá-la para reconhecer dígitos manuscritos. Até lá.
Referências:
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition
Gradient Descent For Machine Learning
Pattern Recognition and Machine Learning
Understanding Activation Functions in Neural Networks
Redes Neurais, princípios e práticas
Neural Networks and Deep Learning
An overview of gradient descent optimization algorithms
Optimization: Stochastic Gradient Descent
Gradient Descent vs Stochastic Gradient Descent vs Mini-Batch Learning