

Capítulo 100 – Machine Learning – Guia Definitivo – Parte 10
Chegamos ao final do Deep Learning Book. Este é o centésimo e último capítulo deste livro online, em português e gratuito, com 100 capítulos!
Antes de mais nada nós da DSA gostaríamos de agradecer a você que acompanhou todo este trabalho realizado até aqui.
O Deep Learning Book nasceu do nosso inconformismo em ver pouco conhecimento sendo gerado em português sobre uma das tecnologias mais revolucionárias da história humana, a Inteligência Artificial. Este livro online, bem como os cursos gratuitos que oferecemos em nosso portal, fazem parte da nossa contribuição para ajudar a disseminar o conhecimento e a educação, tão importantes para a evolução do país.
Hoje o Deep Learning Book é uma referência em língua portuguesa, sendo usado aliás como referência em trabalhos de Mestrado e Doutorado, trabalhos de conclusão de curso de Graduação e Pós-Graduação e desde que foi lançado recebe um volume cada vez maior de acessos. Nosso objetivo vem sendo alcançado e estamos ajudando pessoas interessadas em aprender Inteligência Artificial.
Para concluir este trabalho, vamos fazer uma revisão do processo de aprendizado de máquina com as 10 últimas regras do Guia Definitivo de Machine Learning.
E ao final apresentaremos os programas de capacitação oferecidos pela Data Science Academy.
Boa leitura.
Inteligência Artificial já está presente em nossas vidas. Observe a sua volta. Aplicações de filtro de spam, sistemas de reconhecimento facial no celular, chatbots de atendimento ao cliente, sistemas de recomendação e muito, muito mais.
Pelo menos desde a década de 50 que cientistas ao redor do mundo estão tentando reproduzir nas máquinas o que considera-se como inteligência, reproduzindo especialmente o sistema de aprendizado do cérebro humano.
Mas foi a partir do surgimento do Big Data, e em especial do processamento paralelo em GPUs, pouco mais de uma década atrás, que a Inteligência Artificial cresceu de forma exponencial, permitindo a criação de aplicações maravilhosas em áreas como Visão Computacional e Processamento de Linguagem Natural, notadamente as tarefas mais complexas de reproduzir em computadores.
E uma sub-área da IA, Machine Learning, teve os avanços mais incríveis, quando uma arquitetura em especial, Deep Learning, conseguiu obter resultados do estado da arte.
Mas se você acompanhou este livro com atenção deve ter percebido que muito do que fazemos em IA se resume a Matemática com programação de computadores, através do treinamento com muitos, muitos dados. Aplicando as mais diversas técnicas matemáticas e estatísticas, preparamos os dados, treinamos algoritmos via programação e modelos são criados para os mais devidos fins, resolvendo problemas de negócio, ajudando tomadores de decisão ou alimentando aplicações. E muito ainda está por vir, à medida que as empresas percebem os benefícios de aplicações baseadas em IA.
Aqui estão as 10 regras finais do Guia Definitivo de Machine Learning.
Regra 41: Precisamos de Dados
Você pode pensar: “Espere, isso é óbvio”. Você ficaria surpreso com a quantidade de pessoas que não compreendem que IA, Machine Learning ou Deep Learning não existem sem dados. Precisamos de dados históricos para que, através de algoritmos, possamos detectar padrões e então o modelo realizar suas previsões ou tarefa final.
Para compreender bem isso, basta fazer uma analogia com o aprendizado de uma criança. Como uma criança aprende a falar? Ouvindo sua família falar o tempo todo (a voz representa os dados nesse caso). Como uma criança aprende a escrever? Quando alguém a ensina através de exercícios (que nesse caso representam os dados). Ou seja, uma criança aprende à medida que é exposta a dados, que são processados através dos sentidos e criam no cérebro a memória que será usada pela criança durante toda a sua vida.
Se a sua empresa ainda não está cuidando dos dados com o devido valor, ela já está bem atrasada. Os dados são agora um ativo corporativo mais importante do que nunca e que permite o uso e benefícios de Inteligência Artificial.
Isso explica por que a engenharia de dados também cresceu muito nos últimos anos, uma vez que precisamos de mecanismos, sistemas e ferramentas para coletar, armazenar e processar os dados.
Regra 42: Os Dados Raramente Estarão Prontos Para Uso
E por isso a etapa de limpeza e pré-processamentos dados ainda é parte crucial do trabalho. São várias técnicas que devem ser usadas de acordo com o conjunto de dados.
Raramente os dados estarão no formato ideal para o processo de análise ou construção dos modelos. A criação de pipelines de dados é o que permite passar os dados por uma “linha de produção”, para que os dados cheguem ao seu destino em condições de serem usados. Para compreender isso faça uma analogia: O petróleo bruto poderia ser usado como combustível em um automóvel? Não. Logo, o petróleo passa a ser valioso quando é processado e gera como produto final o combustível que, aí sim, ajudará a resolver diversos problemas (embora também crie outros). Com os dados a ideia é a mesma.
Regra 43: Não Há Arquitetura Ideal em Machine Learning
Machine Learning está distante da perfeição. Cada arquitetura tem pontos fortes e fracos e nosso trabalho não é buscar perfeição e sim encontrar a melhor solução possível, uma aproximação, que será suficiente para resolver determinado problema de negócio.
Não desperdice seu tempo buscando o modelo perfeito. Mantenha o foco na solução do problema e tente encontrar o modelo que oferece a melhor aproximação com o menor esforço.
Regra 44: Machine Learning Não é Aplicação Pronta
Um equívoco muito comum cometido por iniciantes é achar que Machine Learning é uma aplicação pronta, linda e maravilhosa, que pode ser usada imediatamente. Não. Machine Learning cria um modelo e ainda precisamos dar um passo adiante e decidir como usar esse modelo.
O modelo pode ser usado via linha de comando em nossas máquinas, pode ser integrado em uma aplicação web, uma aplicação para smartphone, podemos criar uma API usando um serviço em nuvem. As opções são inúmeras, mas Machine Learning concentra o conhecimento para criação do modelo e não criação da uma aplicação completa.
Regra 45: Use Transfer Learning Sempre Que Possível
Quando seu conjunto de dados consiste em dados não estruturados, como imagens, texto ou áudio, é recomendável pegar carona em modelos pré-treinados existentes.
Para ajustar um classificador de imagens, você pode precisar de apenas 10 exemplos por classe, por exemplo. Frameworks como TensorFlow e PyTorch oferecem uma variedade de modelos pré-treinados. Você não precisa reinventar a roda ou gastar horas ou mesmo dias para treinar um modelo a partir do zero. Aprenda a trabalhar com Transfer Learning e mantenha o foco no seu objetivo. Seu objetivo não é criar modelos e sim resolver problemas de negócio. Aprenda a usar Transfer Learning.
Regra 46: Generalização Através de Regularização
Ao criar um modelo de Machine Learning queremos que ele seja generalizável, ou seja, depois de aprender com dados de treino o modelo deve ser capaz de fazer previsões ou extrair padrões em novos conjuntos de dados. Generalização significa que o modelo não deve aprender os detalhes dos dados de treino, mas sim a relação matemática geral nos dados.
Uma maneira de ajudar seu modelo a generalizar além do conjunto de treinamento é colocar penalidades no tamanho dos pesos w do seu modelo. Isso se chama regularização. Duas penalidades populares são a norma de Manhattan (ou norma L₁) e a norma euclidiana “padrão” (ou norma L₂).
Ao regularizar, verifique se todos os recursos são dimensionados para ordenar a unidade (sem dimensão) por padronização. Isso garante que a penalidade afete todos os pesos igualmente. As estimativas de Ball Park podem ser obtidas estudando dois casos de regressão linear que podem ser resolvidos de forma fechada, a saber, Regressão Lasso (isto é, L₁ regularização λ₁|w|₁ de pesos w) e Regressão de Ridge (L₂ regularização λ₂|w|²₂ de pesos W). Quando os recursos são centrados e não correlacionados, suas soluções podem ser expressas em termos da solução não penalizada.
A Regularização LASSO corta (ou trunca) todos os coeficientes não penalizados abaixo de λ₁. Um ponto de partida razoável pode, portanto, ser λ₁ = 0,1.
A Regularização Ridge, por outro lado, apenas diminui o tamanho para zero. Para escolher λ₂, você pode querer levar em consideração até que ponto seu sistema está sobreajustado (overfitting).
Uma nota de advertência: O Scikit-Learn usa convenções ligeiramente diferentes para os objetivos em Ridge e Lasso.
Regra 47: Qual o Volume de Dados Ideal Para Treinar Modelos de Machine Learning?
Não existe regra mágica, mas a figura abaixo apresenta um ponto de partida:
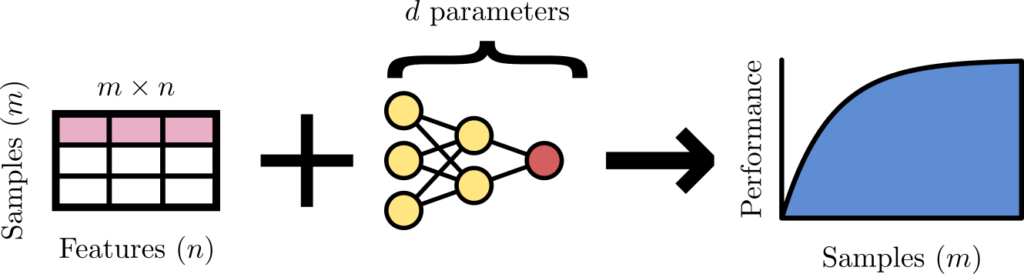
Número de amostras (m), recursos (n) e parâmetros de modelo (d) formam a santíssima trindade do aprendizado de máquina. A maioria das regras de ouro pode ser amplamente trazida de volta a esta tríade.
Regra 48: Quantas Amostras Para Treinar Modelos de Machine Learning?
O desempenho normalmente escala como log m, onde m é o número de amostras e geralmente é limitado pelo ruído nos rótulos. Portanto, quando os dados de treinamento são rotulados por humanos, esse limite geralmente corresponde ao desempenho de nível humano. Logo, pode ser útil focar na qualidade dos dados, em vez da quantidade, conforme sugerido pelo movimento de IA centrada em dados.
Em geral, mais amostras são necessárias para problemas de regressão do que para problemas de classificação.
Regra 49: Quantos Parâmetros?
Lembre-se de sua aula de álgebra linear lá no ensino médio, que para resolver um sistema linear com d graus de liberdade, você precisa de d restrições. Para regressão linear, cada amostra é uma restrição.
Portanto, para fixar os parâmetros d, você precisa de pelo menos tantas amostras — caso contrário, seu sistema é considerado subdeterminado. De forma mais geral, ao interpretar os parâmetros de um modelo como graus de liberdade, uma heurística comum é um sistema dez vezes sobredeterminado:
d ≤ m/10
embora limites mais conservadores para redes neurais, como d ≤ m/50, também sejam sugeridos. Por sua vez, ter determinado o número de parâmetros, d, pode ajudá-lo a decidir se o número de recursos, n, precisa ser reduzido.
No entanto, é necessário cautela porque para muitos modelos, por exemplo, modelos probabilísticos, o número de restrições pode ser O(n) e independente do tamanho da amostra m.
Regra 50: Não Termina Aqui. Isso Foi Só o Começo
Existem 3 fases do aprendizado:
- Fase 1 – Você não sabe o que não sabe.
- Fase 2 – Você sabe o que não sabe.
- Fase 3 – Você sabe o que sabe.
Há muito ainda para aprender sobre Inteligência Artificial e este livro foi apenas o começo! Ao finalizar a leitura deste livro esperamos que você tenha passado da Fase 1 para a Fase 2, quando o assunto é aprendizado de máquina.
Sucesso na sua jornada!
E se você está em busca de capacitação de alto nível, profissional, de qualidade, baseada em projetos e orientada às reais necessidades do mercado de trabalho, oferecemos um conjunto de Formações e Programas de Pós-graduação. Tudo 100% online, em português e com certificado de conclusão que pode ser obtido em português e/ou inglês.
Na Formação o aluno tem o conhecimento prático através de material de alta qualidade e conteúdo baseado em projetos orientados às necessidades do mercado de trabalho. A Formação é um curso livre de aperfeiçoamento profissional e qualquer pessoa pode fazer um curso livre, o único pré-requisito é ter noções de sistemas operacionais. Na Pós-Graduação o aluno tem o mesmo material prático da Formação, incluindo o módulo de Pós que traz apoio de carreira, materiais complementares, criação de portfólio de projetos, exame teórico e exame prático, além do certificado reconhecido pelo MEC. E o módulo de Pós deve ser concluído em até 12 meses.
Quem deseja o conhecimento, pode fazer a Formação. Quem deseja conhecimento mais reconhecimento do MEC pode fazer a Pós. Confira abaixo os programas que oferecemos, faça sua inscrição e eleve sua carreira profissional a outro nível.
Formações
Programas de Pós-Graduação
Obrigado
Equipe DSA