

Capítulo 80 – Melhorando a Compreensão da Linguagem Por Meio do Pré-treinamento Generativo (GPT-1)
Para compreender o GPT-3, seu estado atual e seu uso futuro, é importante dar alguns passos atrás e compreender os modelos predecessores, o GPT-1 e o GPT-2.
Começamos pela versão 1. Aqui está o paper original do modelo GPT-1: Improving Language Understanding by Generative Pre-Training.
Antes dos modelos GPT, a maioria dos modelos de Processamento de Linguagem Natural (PLN) de última geração eram treinados especificamente em uma tarefa particular, como classificação de sentimento, classificação textual, etc., usando aprendizado supervisionado. No entanto, os modelos supervisionados têm duas limitações principais:
- Eles precisam de uma grande quantidade de dados anotados para aprender uma tarefa específica que muitas vezes não está facilmente disponível.
- Eles falham em generalizar para tarefas diferentes daquelas para as quais foram treinados (comum em qualquer modelo de Machine Learning tradicional).
O modelo GPT-1 propôs aprender um modelo de linguagem generativa usando dados não rotulados e, em seguida, ajustar o modelo, fornecendo exemplos de tarefas posteriores específicas, como análise de sentimento, classificação textual, etc.
A aprendizagem não supervisionada serviu como objetivo de pré-treinamento para modelos supervisionados e ajustados, daí o nome de Pré-treinamento Generativo.
Vamos examinar os conceitos e abordagens discutidos no paper do GPT-1.
1. Objetivos e Conceitos de Aprendizagem: Este aprendizado semi-supervisionado (pré-treinamento não supervisionado seguido de ajuste fino supervisionado) para tarefas de PLN tem os seguintes três componentes:
a) Modelagem de Linguagem Não Supervisionada (Pré-treinamento): Para aprendizagem não supervisionada, o objetivo do modelo de linguagem padrão foi usado, conforme a fórmula abaixo.
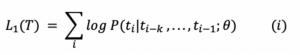
onde T era o conjunto de tokens em dados não supervisionados {t_1,…, t_n}, k era o tamanho da janela de contexto, θ eram os parâmetros da rede neural treinada usando gradiente estocástico descendente.
b) Ajuste Fino Supervisionado: Esta parte tem como objetivo maximizar a probabilidade de observar o rótulo y para determinados recursos ou tokens x_1,…, x_n.
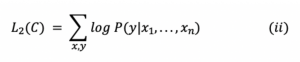
onde C era o conjunto de dados rotulado composto de exemplos de treinamento.
Em vez de simplesmente maximizar o objetivo mencionado na equação (ii), os autores adicionaram um objetivo de aprendizagem auxiliar para o ajuste fino supervisionado para obter melhor generalização e convergência mais rápida. O objetivo de treinamento modificado foi declarado como:
![]()
onde L₁(C) era o objetivo auxiliar do modelo de aprendizagem da linguagem e λ era o peso dado a este objetivo secundário de aprendizagem. λ foi definido como 0,5.
O ajuste fino supervisionado foi obtido adicionando uma camada linear e uma softmax ao modelo do transformador para obter os rótulos de tarefa para tarefas posteriores. Muito similar a outros modelos que vi ao longo deste livro.
c) Transformações de Entradas Específicas da Tarefa: Para fazer alterações mínimas na arquitetura do modelo durante o ajuste fino, as entradas para as tarefas específicas foram transformadas em sequências ordenadas. Os tokens foram reorganizados da seguinte maneira:
– Os tokens de início e fim foram adicionados às sequências de entrada.
– Um token delimitador foi adicionado entre as diferentes partes do exemplo para que a entrada pudesse ser enviada como uma sequência ordenada.
Para tarefas como responder a perguntas, perguntas de múltipla escolha, etc., várias sequências foram enviadas para cada exemplo. Por exemplo. um exemplo de treinamento composto de sequências para contexto, pergunta e resposta para a tarefa de responder a perguntas.
2. Conjunto de Dados: GPT-1 usou o conjunto de dados BooksCorpus para treinar o modelo de linguagem. BooksCorpus tinha cerca de 7.000 livros não publicados que ajudaram a treinar o modelo de linguagem em dados não vistos. É improvável que esses dados sejam encontrados no conjunto de teste. Além disso, esse corpus tinha grandes trechos de texto contíguo, o que ajudou o modelo a aprender dependências de grande alcance.
3. Arquitetura do Modelo e Detalhes de Implementação: GPT-1 usou a estrutura do transformador do decodificador de 12 camadas apenas com autoatenção mascarada para treinar o modelo de linguagem. A arquitetura do modelo permaneceu a mesma em grande medida, conforme descrito no trabalho original sobre transformadores. O mascaramento ajudou a alcançar o objetivo do modelo de linguagem em que o modelo de linguagem não tinha acesso às palavras subsequentes à direita da palavra atual. A seguir estão os detalhes de implementação:
a) Para Treinamento Não Supervisionado:
- O vocabulário Byte Pair Encoding (BPE) com 40.000 fusões foi usado.
- O modelo usou o estado de 768 dimensões para codificar tokens em embeddings de palavras. Embeddings de posição também foram aprendidos durante o treinamento.
- O modelo de 12 camadas foi usado com 12 cabeças de atenção em cada camada de autoatenção.
- Para a posição de alimentação para a frente, a camada 3072 de estado dimensional foi usada.
- O otimizador Adam foi usado com taxa de aprendizado de 2,5e-4.
- Atenção, residuais e dropouts de embeddings foram utilizadas para regularização, com taxa de dropout de 0,1. A versão modificada da regularização L2 também foi usada para pesos sem polarização.
- GELU foi usado como função de ativação.
- O modelo foi treinado por 100 épocas em minilotes de tamanho 64 e comprimento de sequência de 512. O modelo tinha 117M parâmetros no total.
b) Para Ajuste Fino Supervisionado: O ajuste fino supervisionado levou apenas 3 épocas para a maioria das tarefas posteriores. Isso mostrou que a modelo já havia aprendido muito sobre o idioma durante o pré-treinamento. Portanto, o ajuste fino mínimo foi suficiente. A maioria dos hiperparâmetros do pré-treinamento não supervisionado foi usada para o ajuste fino.
4. Desempenho e Resumo: O GPT-1 teve um desempenho melhor do que os modelos de última geração supervisionados especificamente treinados em 9 das 12 tarefas nas quais os modelos foram comparados. Outra conquista significativa deste modelo foi seu desempenho decente de tiro zero em várias tarefas. O artigo demonstrou que o modelo evoluiu em desempenho zero shot em diferentes tarefas de PLN, como responder a perguntas, resolução de esquema, análise de sentimento, etc. devido ao pré-treinamento. O GPT-1 provou que o modelo de linguagem serviu como um objetivo pré-treinamento eficaz que poderia ajudar a generalizar bem o modelo. A arquitetura facilitou a transferência de aprendizado e pode realizar várias tarefas de PLN com muito pouco ajuste. Este modelo mostrou o poder do pré-treinamento generativo e abriu caminhos para outros modelos que poderiam desencadear melhor esse potencial com conjuntos de dados maiores e mais parâmetros.
O GPT-1 agrega muitas das técnicas de Deep Learning que vimos nos capítulos deste livro, sendo o ápice até então. Mas logo depois os pesquisadores do OpenAI (autores do GPT) se superaram e lançaram o GPT-2, que estudaremos no próximo capítulo.
Referências: