

Capítulo 59 – Principais Tipos de Redes Neurais Artificiais Autoencoders
Neste capítulo vamos estudar os tipos principais de Autoencoders (estamos considerando que você leu o capítulo anterior):
Os Autoencoders codificam os valores de entrada x usando uma função f. Em seguida, decodificam os valores codificados f (x) usando uma função g para criar valores de saída idênticos aos valores de entrada. O objetivo do Autoencoder é minimizar o erro de reconstrução entre a entrada e a saída. Isso ajuda os Autoencoders a aprender os recursos importantes presentes nos dados. Quando uma representação permite uma boa reconstrução de sua entrada, ela retém grande parte das informações presentes na entrada.
E existem diferentes tipos de Autoencoders. Confira:
1. Autoencoder Padrão
Na sua forma mais simples, o Autoencoder é uma rede neural artificial de três camadas, isto é, uma rede neural com uma camada de entrada, uma oculta e uma camada de saída. A entrada e a saída são as mesmas e aprendemos a reconstruir a entrada, por exemplo, usando o otimizador adam e a função de perda de erro quadrático médio.
2. Autoencoder Multicamada
Se uma camada oculta não for suficiente, obviamente podemos estender o Autoencoder para mais camadas ocultas. Nossa implementação poderia usar 3 camadas ocultas em vez de apenas uma. Qualquer uma das camadas ocultas pode ser escolhida como representação de recurso, mas o ideal é tornar a rede simétrica e usar a camada mais intermediária.
3. Autoencoder Convolucional
Também podemos nos perguntar: os Autoencoders podem ser usados com convoluções em vez de camadas totalmente conectadas?
A resposta é sim e o princípio é o mesmo, mas usando imagens (vetores 3D) em vez de vetores 1D achatados (flattened). A imagem de entrada é reduzida para fornecer uma representação latente de dimensões menores e forçar o Autoencoder a aprender uma versão compactada das imagens.
4. Autoencoder Regularizado
Existem outras maneiras pelas quais podemos restringir a reconstrução de um Autoencoder, além de impor uma camada oculta de menor dimensão que a entrada. Em vez de limitar a capacidade do modelo mantendo o codificador e o decodificador rasos e o tamanho do código pequeno, os Autoencoders regularizados usam uma função de perda que incentiva o modelo a ter outras propriedades além da capacidade de copiar sua entrada para sua saída. Na prática, geralmente encontramos dois tipos de Autoencoder Regularizado: o Autoencoder Esparso e o Autoencoder Denoising.
4.1. Autoencoder Esparso
Os Autoencoders Esparsos geralmente são usados para aprender recursos para outra tarefa, como classificação. Um Autoencoder que foi regularizado para ser esparso deve responder a recursos estatísticos exclusivos do conjunto de dados em que foi treinado, em vez de simplesmente atuar como uma função de identidade. Dessa forma, o treinamento para executar a tarefa de cópia com uma penalidade de escassez pode produzir um modelo que aprendeu recursos úteis como subproduto.
Outra maneira de restringir a reconstrução do Autoencoder é impor uma restrição à sua perda. Poderíamos, por exemplo, adicionar um termo de reguralização na função de perda. Isso fará com que nosso Autoencoder aprenda representação esparsa de dados. Em nossa camada oculta, podemos adicionar um regularizador de atividades L1, que aplicará uma penalidade na função de perda durante a fase de otimização. Como resultado, a representação será mais esparsa em comparação com o Autoencoder Padrão. Abaixo uma representação do Autoencoder Esparso:
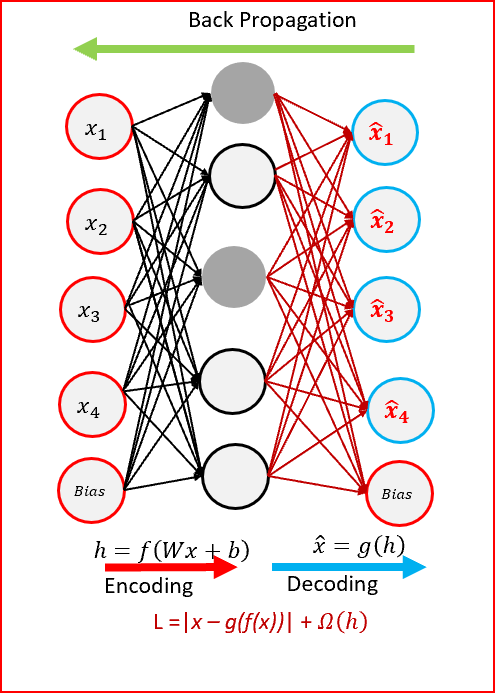
4.2. Autoencoder Denoising
Em vez de adicionar uma penalidade à função de perda, podemos obter um Autoencoder que aprende algo útil alterando o termo do erro de reconstrução da função de perda. Isso pode ser feito adicionando algum ruído à imagem de entrada e fazendo o Autoencoder aprender a removê-la. Dessa maneira, o Autoencoder extrairá os recursos mais importantes e aprenderá uma representação robusta dos dados.
Denoising refere-se à adição intencional de ruído à entrada bruta antes de fornecê-la à rede. Pode-se obter denoising usando o mapeamento estocástico. Abaixo uma representação do Autoencoder Denoising:
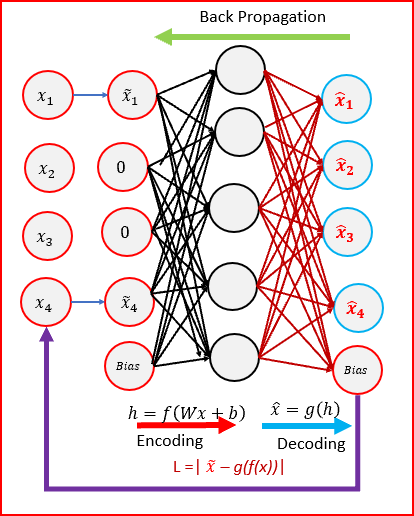
5. Contractive Autoencoders(CAE)
O objetivo do Autoencoder Contrativo (CAE) é ter uma representação aprendida robusta, menos sensível a pequenas variações nos dados. A robustez da representação para os dados é feita aplicando um termo de penalidade à função de perda. O termo da penalidade é a norma Frobenius da matriz jacobiana. A norma de Frobenius da matriz jacobiana para a camada oculta é calculada em relação à entrada. A norma de Frobenius da matriz jacobiana é a soma do quadrado de todos os elementos.
O Autoencoder Contrativo é outra técnica de regularização, como os Autoencoders Esparsos e os Autoencoders Denoising.
O CAE supera os resultados obtidos pela regularização do Autoencoder usando decaimento de peso ou denoising. O CAE é uma escolha melhor do que o Autoencoder Denoising para aprender a extração de recursos úteis. O termo de penalidade gera mapeamento que contrai fortemente os dados e, portanto, o nome Autoencoder Contrativo.
6. Deep Autoencoders
Deep Autoencoders consistem em duas redes de crenças profundas idênticas (Deep Belief Networks). Uma rede para codificação e outra para decodificação. Os Autoencoders tipicamente profundos têm de 4 a 5 camadas para codificação e as próximas 4 a 5 camadas para decodificação. Usamos camada não supervisionada por camada, pré-treinamento.
A Máquina Boltzmann Restrita (RBM) é o alicerce básico das Deep Belief Networks. Na figura abaixo, tiramos uma imagem com 784 pixels. Treinamos usando uma pilha de 4 RBMs, desenrolamos e ajustamos com Backpropagation. A camada de codificação final é compacta e rápida!
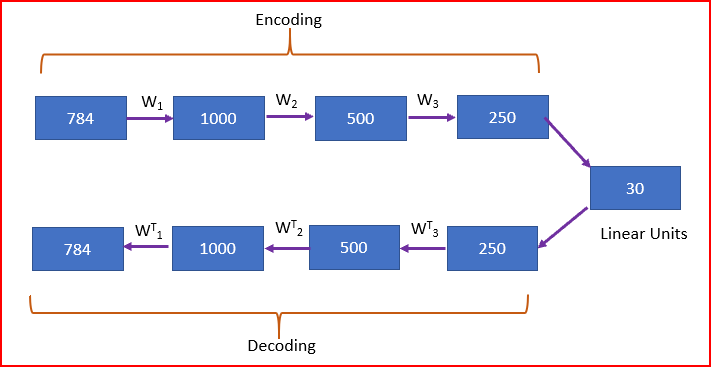
7. Variational Autoencoders (VAEs)
Nos últimos anos, modelos generativos baseados em aprendizado profundo ganharam cada vez mais interesse devido a (e implicando) algumas melhorias surpreendentes no campo. Contando com uma enorme quantidade de dados, arquiteturas de rede bem projetadas e técnicas de treinamento inteligentes, os modelos geradores profundos demonstraram uma capacidade incrível de produzir peças de conteúdo altamente realistas de vários tipos, como imagens, textos e sons. Entre esses modelos geradores profundos, duas famílias principais se destacam e merecem uma atenção especial: Redes Adversárias Generativas (GANs) e Autoencoders Variacionais (VAEs). As GANs já estudamos nos capítulos anteriores.
E a VAE é tão especial que merece um capítulo inteiro. Não perca o próximo capítulo.
Referências:
Customizando Redes Neurais com Funções de Ativação Alternativas
Autoencoders – Unsupervised Learning
Deep Learning — Different Types of Autoencoders
Contractive Auto-Encoders – Explicit Invariance During Feature Extraction
Practical Recommendations for Gradient-Based Training of Deep Architectures
Gradient-Based Learning Applied to Document Recognition
Neural Networks & The Backpropagation Algorithm, Explained
Recurrent neural network based language model
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition