

Capítulo 48 – Redes Neurais Recorrentes
Os humanos não começam a pensar do zero a cada segundo. Ao ler este texto, você entende cada palavra com base em sua compreensão das palavras anteriores. Você não joga tudo fora e começa a pensar de novo. Seus pensamentos têm persistência.
As redes neurais artificiais tradicionais não podem fazer isso, o que traz algumas limitações para esses tipos de modelos. Por exemplo, imagine que você queira classificar o tipo de evento que está acontecendo em todos os pontos de um filme. Não está claro como uma rede neural tradicional poderia usar seu raciocínio sobre eventos anteriores no filme para informar os posteriores.
Redes Neurais Recorrentes resolvem esse problema. São redes com loops, permitindo que as informações persistam.
As redes recorrentes são um tipo de rede neural artificial projetada para reconhecer padrões em sequências de dados, como texto, genomas, caligrafia, palavra falada ou dados de séries numéricas que emanam de sensores, bolsas de valores e agências governamentais. Esses algoritmos consideram tempo e sequência, eles têm uma dimensão temporal.
A pesquisa mostra que eles são um dos tipos mais poderosos e úteis de rede neural, juntamente com o mecanismo de atenção e as redes de memória. As RNNs são aplicáveis até mesmo a imagens, que podem ser decompostas em uma série de amostras e tratadas como uma sequência.
Como as redes recorrentes possuem um certo tipo de memória, e a memória também faz parte da condição humana, faremos analogias com a memória do cérebro, para uma melhor compreensão. Continue a leitura.
Revisão de Redes Feedforward
Para entender as redes recorrentes, primeiro vamos revisar o básico das redes feedforward, que estudamos em capítulos anteriores aqui mesmo no Deep Learning Book.
Ambas as redes recebem o nome da forma como canalizam informações através de uma série de operações matemáticas realizadas nos nós da rede. As redes feedforward alimentam informações diretamente (nunca tocando em um determinado nó duas vezes), enquanto as redes recorrentes percorrem através de um loop.
No caso de redes feedforward, exemplos de entrada são alimentados na rede e transformados em uma saída; com a aprendizagem supervisionada, a saída seria por exemplo um rótulo, um nome aplicado à entrada. Ou seja, elas mapeiam dados brutos para categorias, reconhecendo padrões que podem sinalizar, por exemplo, que uma imagem de entrada deve ser rotulada como “gato” ou “cachorro”. A imagem abaixo mostra um exemplo de rede feedforward.
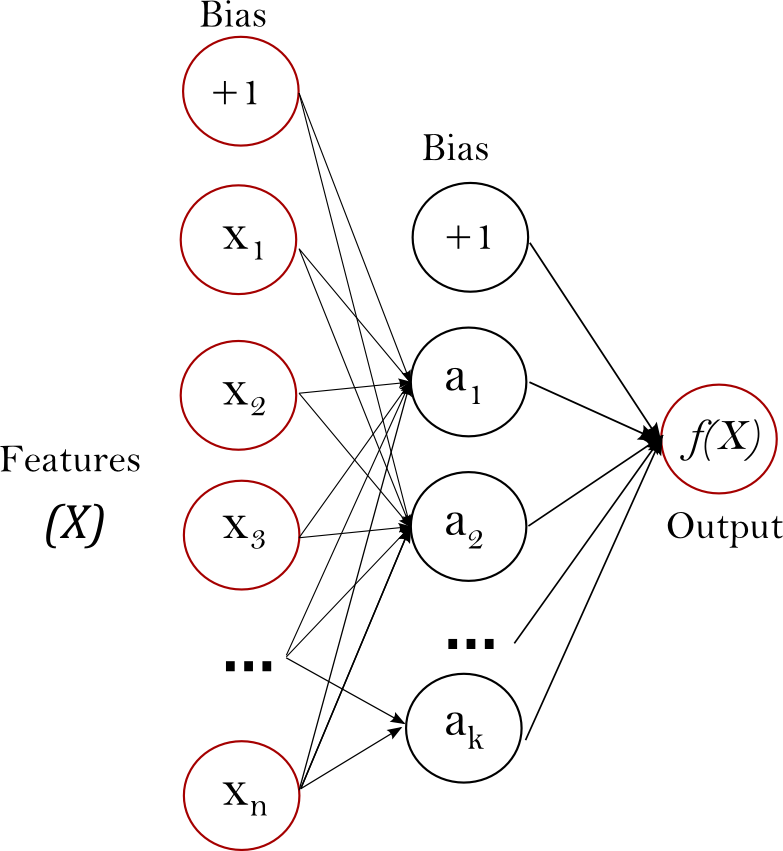
Uma rede feedforward pode então ser treinada em imagens rotuladas, por exemplo, até minimizar o erro ao classificar suas categorias. Com o conjunto treinado de parâmetros (ou pesos, conhecidos coletivamente como um modelo), a rede procura categorizar os dados que nunca viu. Uma rede feedforward treinada pode ser exposta a qualquer coleção aleatória de fotografias, e a primeira fotografia a que está exposta não alterará necessariamente como classifica a segunda. Ver a fotografia de um gato não levará a rede a perceber um cachorro em seguida.
Ou seja, uma rede feedforward não tem noção de ordem no tempo, e a única entrada que considera é o exemplo atual a que foi exposta. As redes feedforward são amnésicas em relação ao seu passado recente; elas lembram nostalgicamente apenas os momentos formativos do treinamento.
Redes Neurais Recorrentes
As redes recorrentes, por outro lado, tomam como entrada não apenas o exemplo de entrada atual que veem, mas também o que perceberam anteriormente no tempo. Aqui está um diagrama com a representação de uma rede neural recorrente e uma rede feedforward.
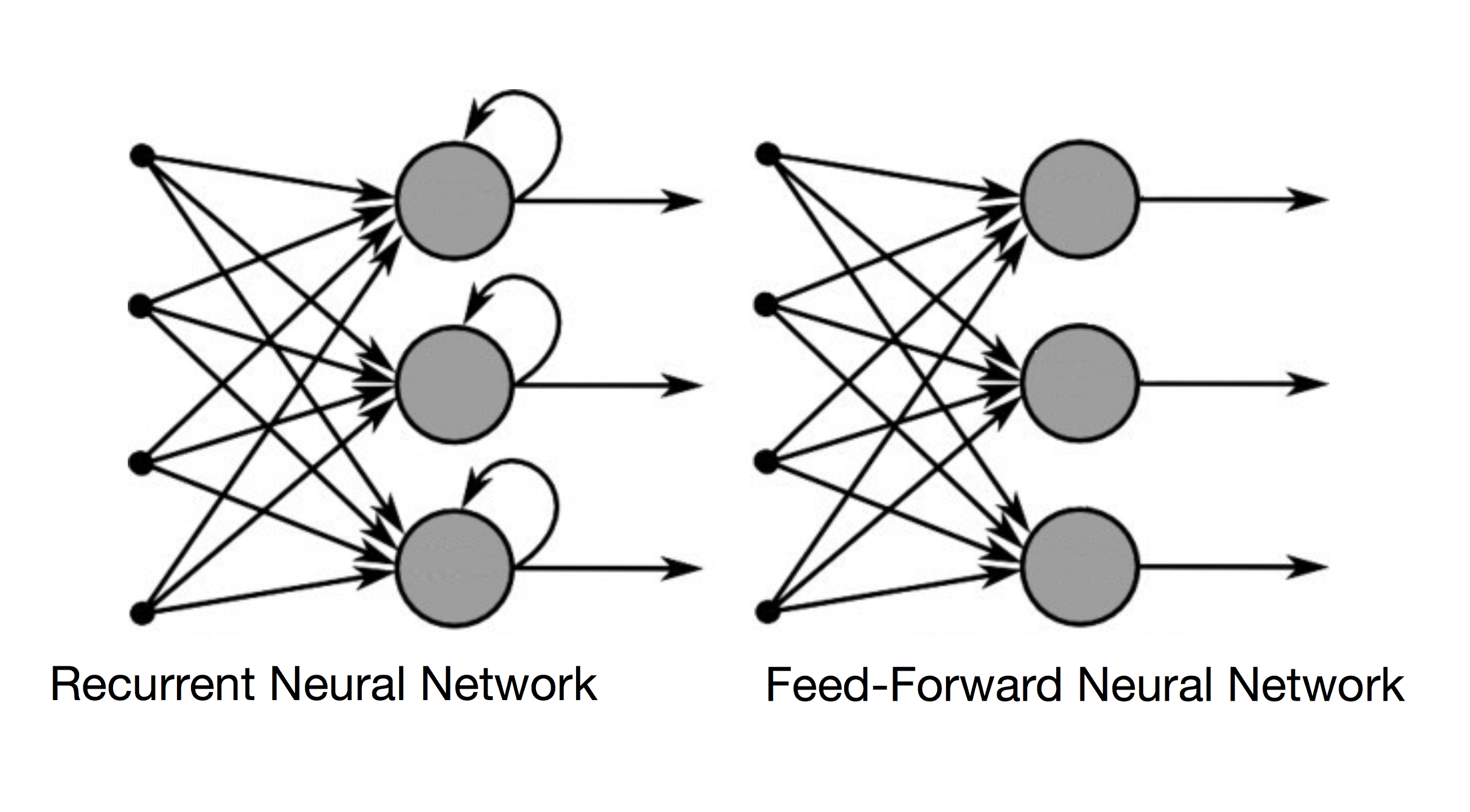
A decisão de uma rede recorrente alcançada na etapa de tempo t-1 afeta a decisão que alcançará um momento mais tarde na etapa de tempo t. Assim, as redes recorrentes têm duas fontes de entrada, o presente e o passado recente, que se combinam para determinar como respondem a novos dados, da mesma forma que fazemos na vida. Nas redes neurais recorrentes isso é feito, claro, com a ajuda da nossa querida Matemática. E por isso o curso Matemática e Estatística Aplicada Para Data Science, Machine Learning e IA é um dos cursos de maior sucesso na Data Science Academy.
As redes recorrentes são diferenciadas das redes feedforward pelo loop de feedback conectado às suas decisões anteriores, ingerindo suas próprias saídas momento após momento como entrada. Costuma-se dizer que as redes recorrentes têm memória. A adição de memória às redes neurais tem uma finalidade: há informações na própria sequência e as redes recorrentes a utilizam para executar tarefas que as redes de feedforward não conseguem.
Essa informação sequencial é preservada no estado oculto da rede recorrente, que consegue passar por muitas etapas de tempo à medida que ela avança em cascata para afetar o processamento de cada novo exemplo. Essas correlações entre eventos são separadas por muitos momentos, e essas correlações são chamadas de “dependências de longo prazo”, porque um evento no tempo depende e é uma função de um ou mais eventos que vieram antes. Uma maneira objetiva de pensar sobre as RNNs é a seguinte: elas são uma forma de compartilhar pesos ao longo do tempo.
Assim como a memória humana circula invisivelmente dentro de um corpo, afetando nosso comportamento sem revelar sua forma completa, a informação circula nos estados ocultos de redes recorrentes. A língua portuguesa está cheia de palavras que descrevem os ciclos de feedback da memória. Quando dizemos que uma pessoa é assombrada por seus atos, por exemplo, estamos simplesmente falando sobre as consequências que as produções passadas causam no tempo presente. Os franceses chamam isso de “Le passé qui ne passe pas” ou “O passado que não passa”.
Descreveremos o processo de levar a memória adiante matematicamente da seguinte forma:
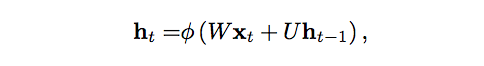
O estado oculto na etapa de tempo t é h_t. É uma função da entrada na mesma etapa de tempo x_t, modificada por uma matriz de peso W (como a que usamos para redes feedforward) adicionada ao estado oculto do passo de tempo anterior h_t-1 multiplicado por seu próprio estado oculto – para a matriz de estado oculto U, também conhecida como matriz de transição e semelhante a uma cadeia de Markov. As matrizes de peso são filtros que determinam quanta importância deve ser dada tanto à entrada atual quanto ao estado oculto do passado. O erro que eles geram retornará por meio de retropropagação (backpropagation) e será usado para ajustar seus pesos até que o erro não diminua mais.
A soma da entrada de peso e do estado oculto é comprimida pela função φ – ou uma função sigmoide logística ou tanh, dependendo – que é uma ferramenta padrão para condensar valores muito grandes ou muito pequenos em um espaço logístico, bem como tornar os gradientes viáveis para retropropagação.
Como esse loop de feedback ocorre a cada etapa da série, cada estado oculto contém traços não apenas do estado oculto anterior, mas também de todos aqueles que precederam h_t-1 pelo tempo que a memória pode persistir.
Dada uma série de letras, uma rede recorrente usará o primeiro caractere para ajudar a determinar sua percepção do segundo caractere, de tal forma que um q inicial possa levá-lo a inferir que a próxima letra será u.
Mas para que as redes neurais recorrentes possam aprender de forma efetiva, precisamos de uma versão levemente modificada do Backpropagation, o BPTT (Backpropagation Through Time). Mas isso é assunto para o próximo capítulo! Estudaremos ainda duas importantes variações das RNNs, as Long Short-Term Memory Units (LSTMs) e as Gated Recurrent Units (GRUs).
Enquanto isso, caso queira começar a se divertir com as RNNs, acompanhe esse tutorial oficial do TensorFlow: Recurrent Neural Networks. Para aulas práticas em português com linguagem Python, acesse aqui.
Referências:
Recurrent Neural Networks Cheatsheet
A Beginner’s Guide to LSTMs and Recurrent Neural Networks
Practical Recommendations for Gradient-Based Training of Deep Architectures
Gradient-Based Learning Applied to Document Recognition
Neural Networks & The Backpropagation Algorithm, Explained
Neural Networks and Deep Learning
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition